CLI node
CLI ノードを使用すると、フロー内のステップとしてカスタム CLI コマンドを実行し、その構造化された出力を次のノードに渡すことができます。スクリプトは安全なサンドボックス環境で実��行されます。AWS または GCP の接続を必ず紐付けてください。スクリプトはその接続の認証情報で実行され、gcloud または aws はあらかじめインストールされています。
CLI ノードはフローを簡素化する際に便利です。例えば、aws ec2 attach-volume コマンドを 1 つの CLI ノードで実行できます。通常の AWS ノードを使う場合は、DescribeInstances(検証)、DescribeVolumes(状態チェック)、AttachVolume の 3 つのノードを連結する必要があります。
Before you begin
CLI ノードを追加する前に、AWS または GCP の接続を作成してください。接続の概要については、Connections を参照してください。
同じ接続を複数のアクションノードや CLI ノードで再利用したい場合は、接続変数を作成してください。
Configure the CLI node
CLI ノードを選択すると、サイドパネルに Parameters タブが表示されます。
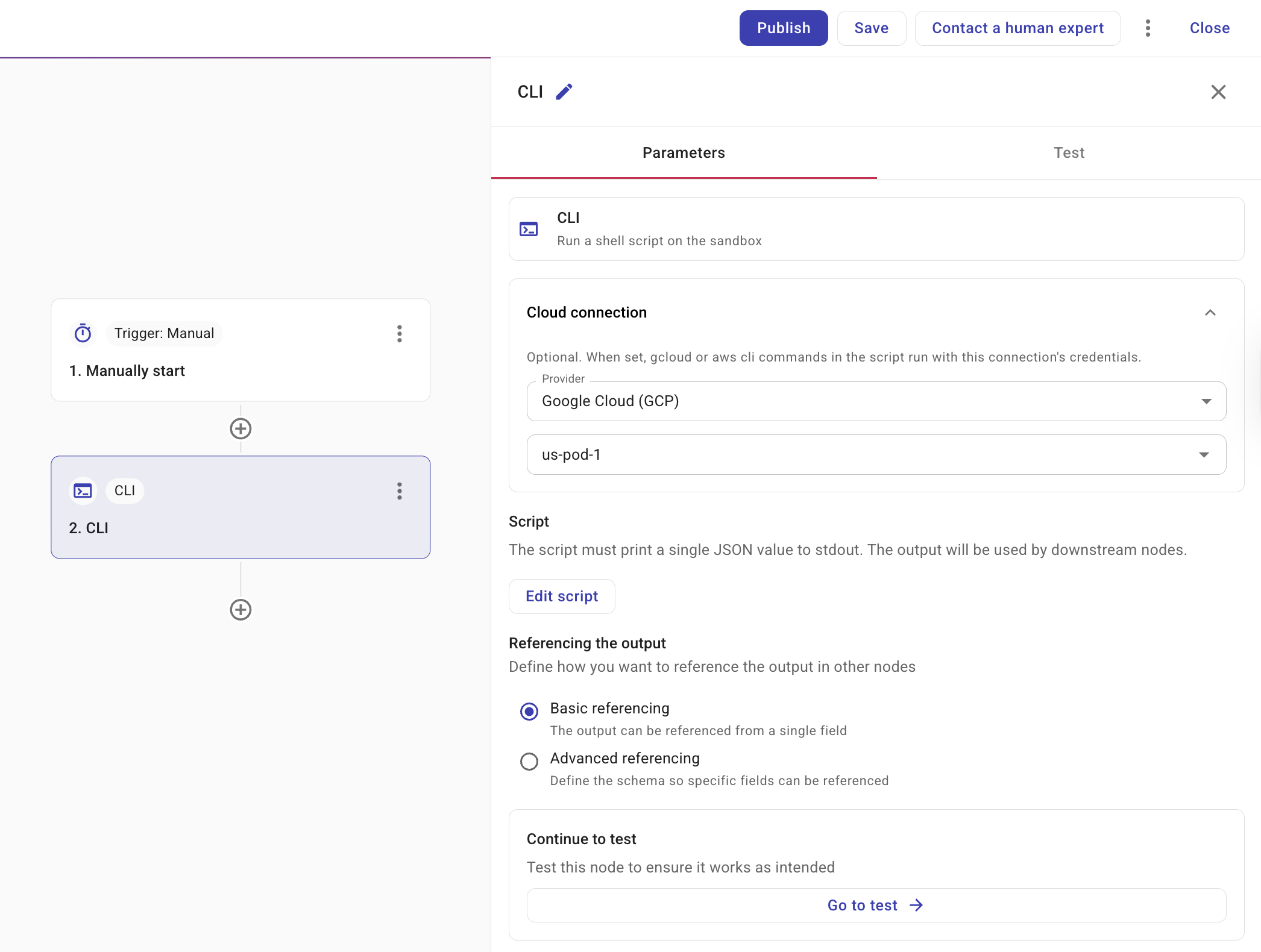
-
Cloud connection provider: Google Cloud (GCP) または Amazon Web Services (AWS) を選択します。ドロップダウンには、組織がアクセスできるプロバイダのみが表示され、最初に利用可能なオプションがデフォルトで選択されます。接続は必須であり、スクリプトはその接続の認証情報で実行されます。
直接接続または接続変数を選択できます。接続変数を使用すると、接続を 1 か所で管理し、複数のノードで再利用できます。Connection ドロップダウンには、接続と接続変数の両方が表示されます。
(AWS のみ)Account と Region: 接続として Amazon Web Services (AWS) を選択している場合は、アカウントと、必要に応じて地域を選択します。設定しない場合、Region は全リージョンがデフォルトになります。
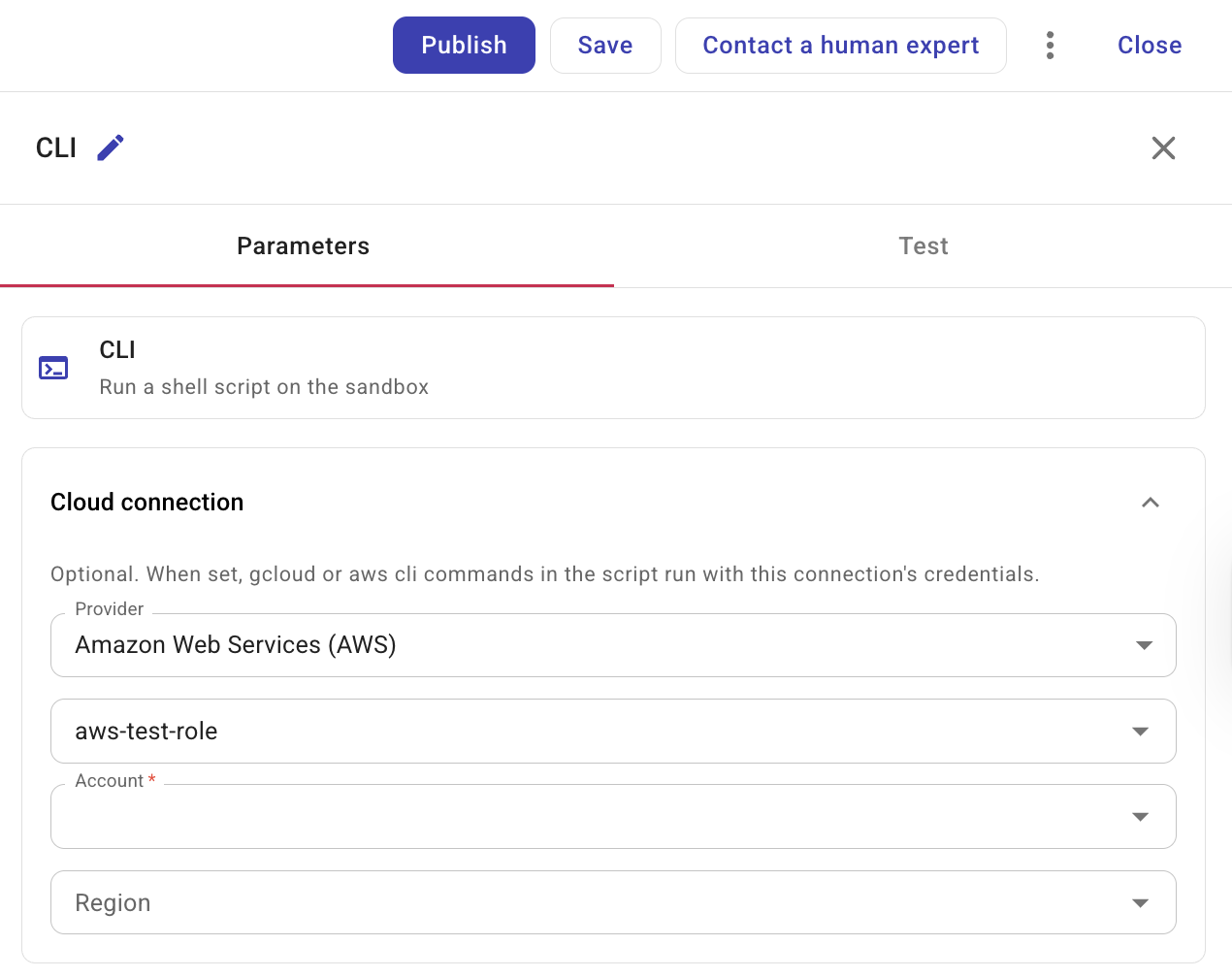
CLI ノードで接続変数を選択すると、CloudFlow はスクリプトを実行する前に、��その変数を基になる接続 ID に解決します。接続変数を更新すると、ノード自体を編集しなくても、CLI ノードが使用する接続を変更できます。
-
Add script または Edit script を選択してスクリプトエディタを開きます。スクリプトはサンドボックス内で実行されます。接続を選択している場合、選択したプロバイダに応じて
gcloudまたはawsが利用可能で、すでに認証されています。標準出力(stdout)には単一の JSON 値を出力してください。後続のノードは、その出力から個々のフィールドを参照したり、条件で使用したり、次のステップへ渡したりできます。そのため、有効な JSON を生成することが、CLI ノードの結果をフロー全体で利用可能にする方法となります。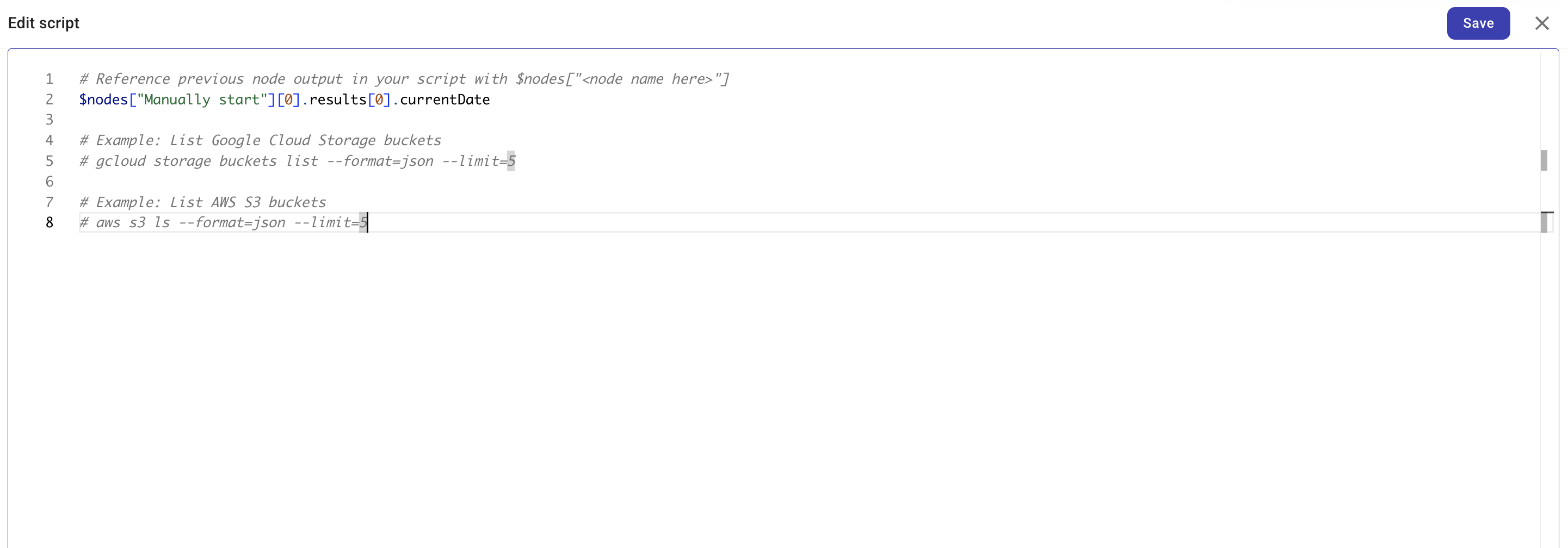
フロー内の前段の任意のノードの出力は、
$nodes["<Node name>"]を使用して参照できます。ネストされた値にアクセスするには、オプションでパスを追加します。例えば$nodes["Manually start"][0].results[0].currentDateのように指定します。# Reference previous node output in your script with $nodes["<node name>"]
echo $nodes["Manually start"][0].results[0].currentDateフローのグローバル変数とローカル変数には
$variablesを使ってアクセスできます。グローバル変数には$variables.globalVariables.<name>、ローカル変数には$variables.localVariables.<name>を使用してください。CloudFlow は、コマンドが実行される前に$nodesと$variablesをテキストインジェクションで処理します。各値は、スペースや特殊文字を扱えるよう自動的にラップされます。Code ノードとは異なり、これらの参照はライブオブジェクトではなく、プレーンテキストに置き換えられます。独自にクオートやバックスラッ�シュを追加する場合は注意してください。CloudFlow の内部フォーマットをさらに外側から囲む形になり、パースエラーの原因となる可能性があります。# Access flow variables
echo $variables.globalVariables.projectRegion
echo $variables.localVariables.retryCountヒントスクリプトエディタは
$nodesと$variables双方の補完機能をサポートしています。ノード名、変数スコープ、変数名を挿入する際に活用してください。 -
Referencing the output: フロー内の他のノードが、この CLI ノードの出力をどのように参照できるかを定義します。後続のノードでこのノードの値を参照する方法(例: + ボタン経由)については、Node parameters を参照してください。
-
Basic referencing: 出力を 1 つのフィールドとして参照します。単純な戻り値に使用します。
-
Advanced referencing: JSON スキーマを定義し、出力内の特定フィールドを後続ノードから個別に参照できるようにします。スキーマの定義方法については、Output schema を参照してください。
-
Execution limits
スクリプトは、次の制限があるサンドボックス環境で実行されます。
-
Sandbox tools: CLI サンドボックスはシェルに加えて、接続に応じて
gcloudまたはawsを提供します。Python などの他のランタイムは利用できません。�上流ノードの出力に対する JSON の変換やフィルタリングには、代わりに Code node を使用してください。 -
Maximum execution time: 最大 10 秒です。これを超えると、ノードはタイムアウトエラーで失敗します。
-
Rate limit: サンドボックス側でレート制限を適用する場合があります。制限を超えると、ノードは rate-limit エラーで失敗します。
GCS object metadata
フロー内で Google Cloud Storage のオブジェクトメタデータが必要な場合は、gcloud を使用して JSON メタデータを直接返してください。
これは GCS オブジェクトのメタデータのみを返します。storage.objects.get アクションで alt=media クエリパラメータを使用する場合を含め、GCS オブジェクトのファイルコンテンツの取得はまだサポートされていません。gcloud を通じてファイルコンテンツをダウンロードおよびフィルタリングするための CLI ノードによる回避策もありません。この制限は、PII やシークレットなどの機密ファイルコンテンツが CloudFlow の結果や実行履歴に保存されることを防ぎ、大容量ファイルに対するシステムの安定性を維持するのに役立ちます。
gcloud storage objects describe gs://my-bucket/path/to/file.csv --format=json
Examples
以下は、CLI ノードで使用できるスクリプト例です。
List GCS buckets
次のスクリプトは、GCP 接続が設定されている場合に Google Cloud Storage の bucket を一覧表示します。コマンドは JSON を直接出力するため、後続ノードは配列全体やそのフィールド(高度な参照とスキーマを使用する場合など)を参照できます。
gcloud storage buckets list --format=json --limit=5
List S3 buckets
AWS 接続とアカウントを選択している場合は、代わりに S3 bucket を一覧表示できます。
aws s3api list-buckets --output json
List running EC2 instances
AWS 接続とアカウントを選択している場合は、稼働中の EC2 インスタンスを一覧表示し、後続ノード用に JSON 配列として返すことができます。AWS CLI はフィルターを適用し、出力の形を整えます。
aws ec2 describe-instances \
--filters "Name=instance-state-name,Values=running" \
--query 'Reservations[].Instances[].{InstanceId:InstanceId,State:State.Name}' \
--output json
上流ノード(例: AWS の Describe instances アクションノード)の出力をフィルタリングまたは変換するには、後続ステップで Code node または Transform・Filter ノードを使用してください。
See also
- Nodes
- Output schema
- Code node — スクリプトと出力の参照
- Connections
- Variables — 接続変数を含む
- Create a GCP connection
- Create an AWS connection