SQL node
SQL ノードは、SQL ノードエディタを使用してフロー内で SQL クエリを実行するために使用します。SQL ノード内に直接クエリを入力し、その結果に基づいてアクションを実行できます。これは、フローにデータドリブンな条件ロジックを取り入れるのに有用であり、DoiT Cloud Intelligence に保存されている請求データに基づいて複雑な意思決定を容易にします。例えば、AWS の請求データをクエリする SQL クエリを作成できます。その出力にフィルターをかけて、最もコストの高いサービスを特定し、ステークホルダーに通知できます。
また、SQL ノードに Google Cloud connection を接続することで、DoiT の請求データと並行して外部の BigQuery データセットをクエリできます。例えば、1 つのクエリでコストを自社の使用状況やプロジェクトのテーブルと結合できます。1 つの SQL クエリの中で DoiT の請求データと外部 BigQuery テーブルを同時に参照することはできません。フロー内で 2 つの SQL ノードを使用する必要があり、1 つは DoiT の請求データをクエリし、もう 1 つは Google Cloud connection を使用して外部 BigQuery データセットをクエリします。
同じフローで 2 つの SQL ノードを使用する場合は、それらを順番につなげてください。最初の SQL ノードの出力はフロー内の後続ノードで利用できます。例えば、Filter ノードでその出力をフィルターしたり、Branch ノードで分岐条件に使ったり、Notification ノードで通知内容に含めたりできます。Query Output Schema を定義して、下流のノードが必要なフィールドを参照できるようにしてください。
DoiT の請求データをクエリする
SQL ノードを使用して、DoiT Cloud Intelligence に保存されている請求データをクエリできます。
SQL クエリ例
以下は、直近 7 日間でコストアロケーションタグが付与され�ていない最もコストの高い AWS リソース 20 件を特定することで、コスト最適化とガバナンスに役立つ SQL クエリの例です。
WITH recent AS (
SELECT
resource_id,
service_description,
SUM(cost) AS untagged_cost_7d
FROM `aws_dci`
WHERE usage_start_time >= TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 7 DAY)
AND (labels IS NULL OR ARRAY_LENGTH(labels) = 0)
GROUP BY resource_id, service_description
)
SELECT
resource_id,
service_description,
ROUND(untagged_cost_7d, 2) AS untagged_cost_7d
FROM recent
WHERE untagged_cost_7d > 5
ORDER BY untagged_cost_7d DESC
LIMIT 20;
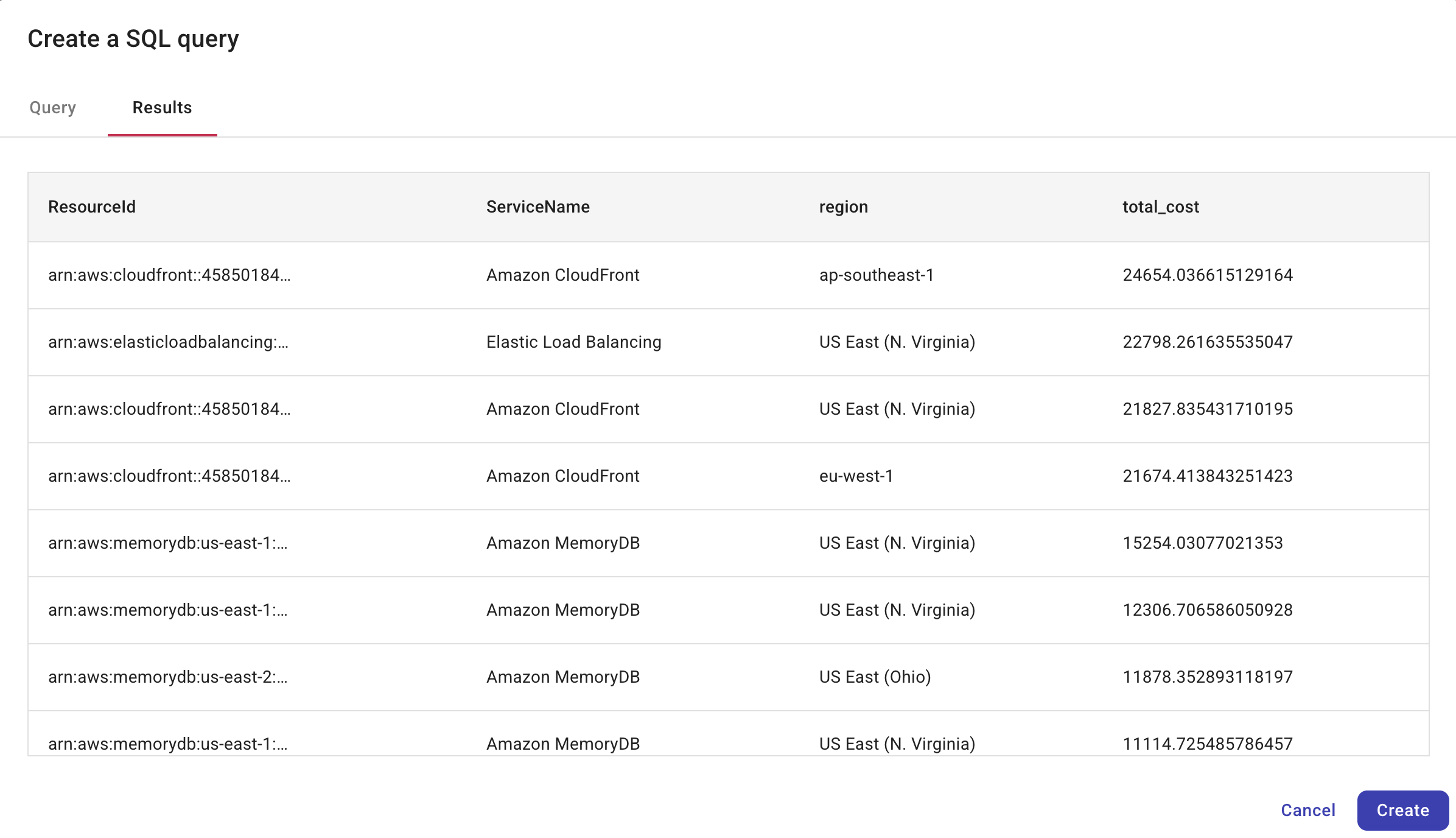
以下は、その結果として得られるテーブルの例で、直ちに対応が必要な AWS リソースの優先度付きリストを示しています。
| resource_id | service_description | untagged_cost_7d |
|---|---|---|
| i-0f23ab91c5d4ef123 | Amazon Elastic Compute Cloud | 142.37 |
| vol-03bc1198a7e9d7812 | Amazon Elastic Block Store | 58.12 |
| arn:aws:lambda:...func1 | AWS Lambda | 27.44 |
| bucket-analytics-prod | Amazon S3 | 12.91 |
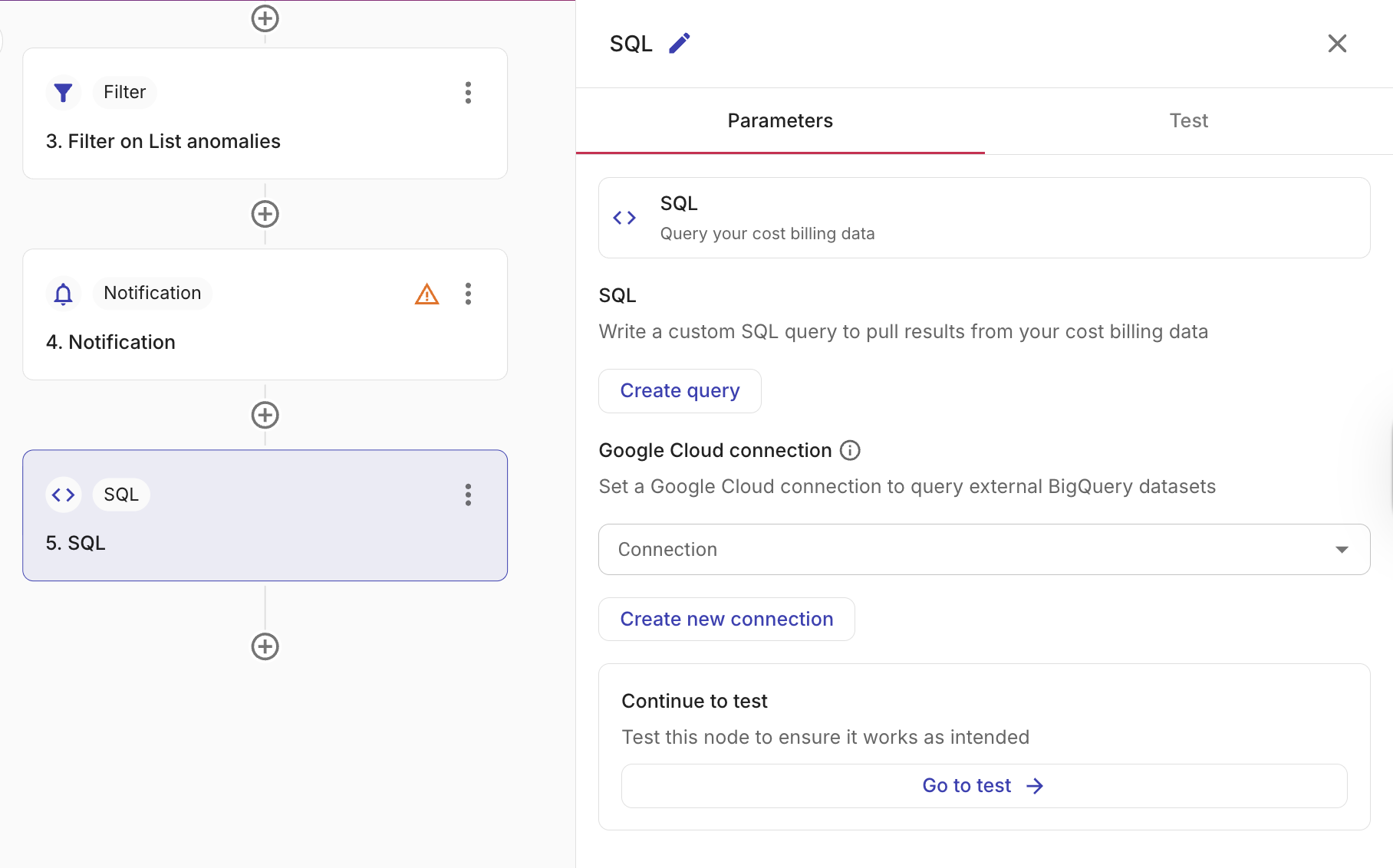
SQL ノードを設定する
SQL ノードを設定するには、クエリを作成してテストし、その後、後続のノードで参照できるフィールドについて予想される出力を確認します。
-
Create query を選択します。Create a SQL query ウィンドウが表示され、SQL クエリを作成およびテストできます。
-
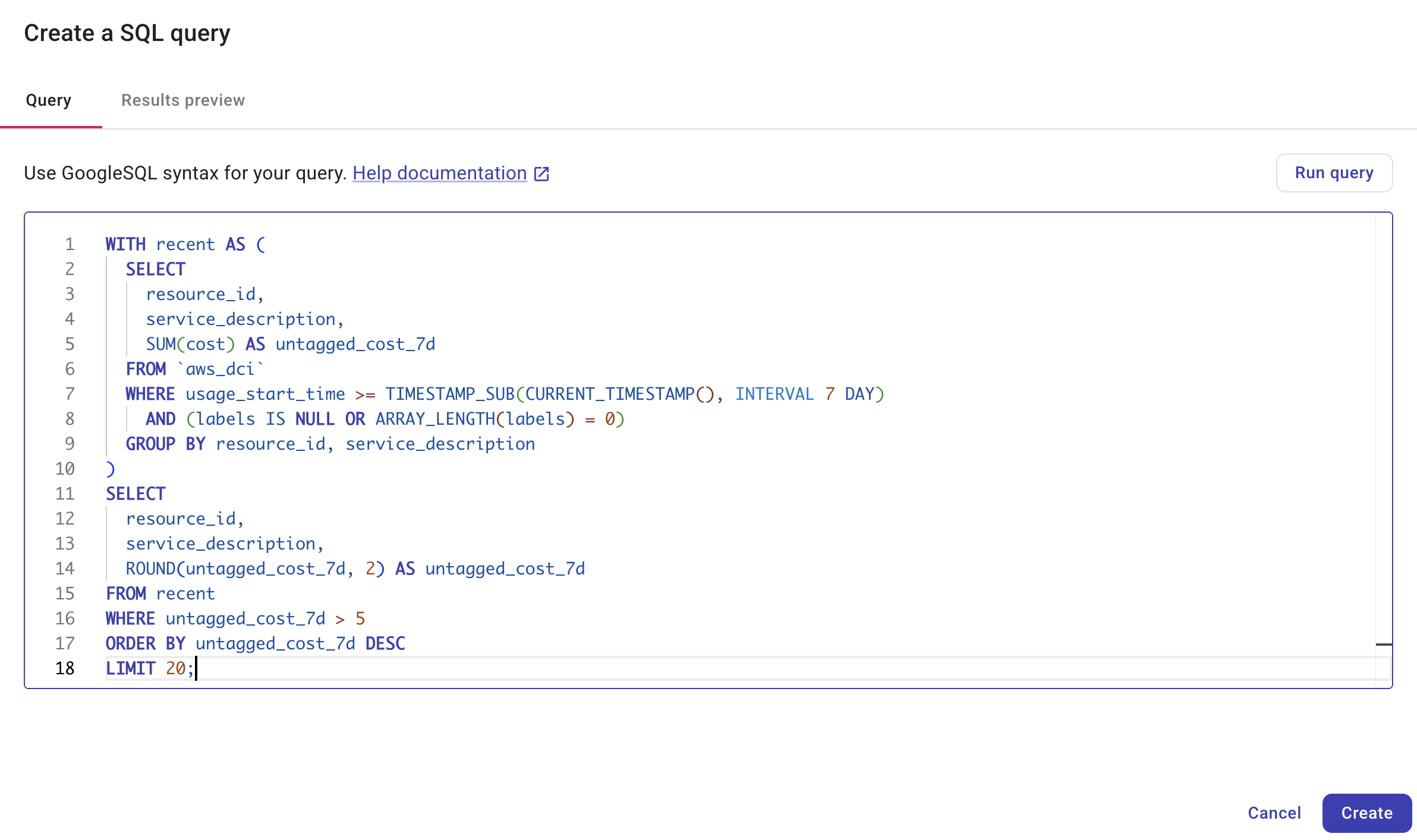
Query タブで SQL クエリを作成します。SQL ノードは GoogleSQL を使用します。入力中に、DoiT Cloud Intelligence が SQL クエリを検証し、構文エラーやその他�の問題の可能性を即座にハイライト表示します。
ヒントFormat を使用して SQL を自動的にインデントおよび改行し、読みやすく編集しやすくしてください。
注意SQL �クエリエディタは、入力中のクエリを自動的に下書きとして保存し、画面遷移時のデータ損失を防ぎます。下書きは 24 時間保存され、デバイス間で同期されません。Save を選択すると、フローへの変更が確定され、ローカルの下書きがクリアされます。下書きが期限切れになった場合、CloudFlow は最後に保存されたバージョンに戻ります。
-
Run query を選択してクエリをテストします。SQL ノードエディタでは、クエリが正常に実行されることが、クエリを作成するための必須条件となっており、検証済みのクエリのみが作成されます。
-
Run を選択すると、結果が Results タブに表示され、クエリのロジック、効率性、およびデータ出力を検証できます。出力スキーマは DoiT の請求データスキーマに準拠します。
-
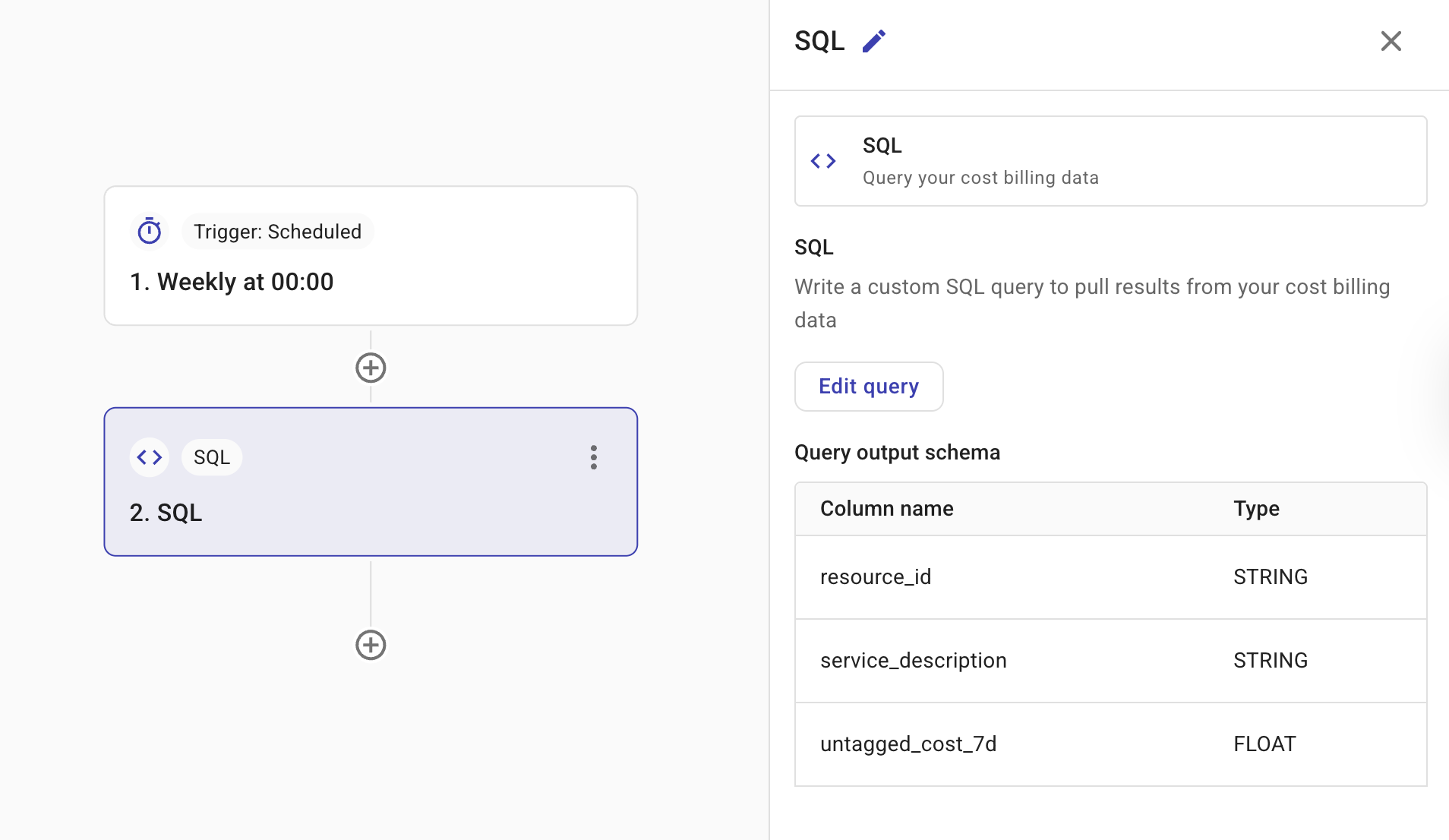
Query Output Schema には、クエリからの予想される出力が表示されます。これらは、後続のノード(例えば + ボタン経由)で参照できるフィールドです。Node parameters を参照してください。
外部 BigQuery データセットをクエリする
オプションとして、SQL ノードに Google Cloud connection を接続し、DoiT Cloud Intelligence の外部に存在する BigQuery データセット(例えば、自社の Google Cloud プロジェクト内のテーブル)をクエリできます。
Connection の権限
SQL ノードで connection を使用するには、その connection へのアクセス権(Owner、Editor、または User)が必要です。アクセス権がない場合、ノードにはエラーが表示され、使用を許可された connection を選択するまで Run query ボタンは無効化されます。
SQL クエリ例
この例では、2 つの外部テーブルを結合して、プロジェクト別の利用状況を分析します。
SELECT
u.user_email,
p.project_name,
SUM(u.compute_hours) as total_hours
FROM `my-project.usage_data.daily_usage` AS u
JOIN `my-project.inventory.projects` AS p
ON u.project_id = p.id
WHERE u.usage_date >= DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY)
GROUP BY 1, 2
ORDER BY total_hours DESC;
以下は、その結果として得られるテーブルの例で、過去 30 日間におけるユーザーおよびプロジェクトごとの合計コンピュート時間を示しています。
| user_email | project_name | total_hours |
|---|---|---|
| [email protected] | production-web | 124.5 |
| [email protected] | analytics-prod | 89.2 |
| [email protected] | staging | 42.0 |
| [email protected] | production-web | 31.8 |
ハイフンを含むテーブル名(例えば外部データセット)には、` を使用してください(例: `bigquery-public-data.bbc_news.fulltext`)。
SQL ノードを設定する
外部 connection を設定するには、次の手順を実行してください。
-
SQL ノードの Parameters タブで、Google Cloud connection セクションまでスクロールします。
-
Connection ドロップダウンから既存の GCP connection を選択します。利用できるのは、アクセス権が付与されている connection のみです。
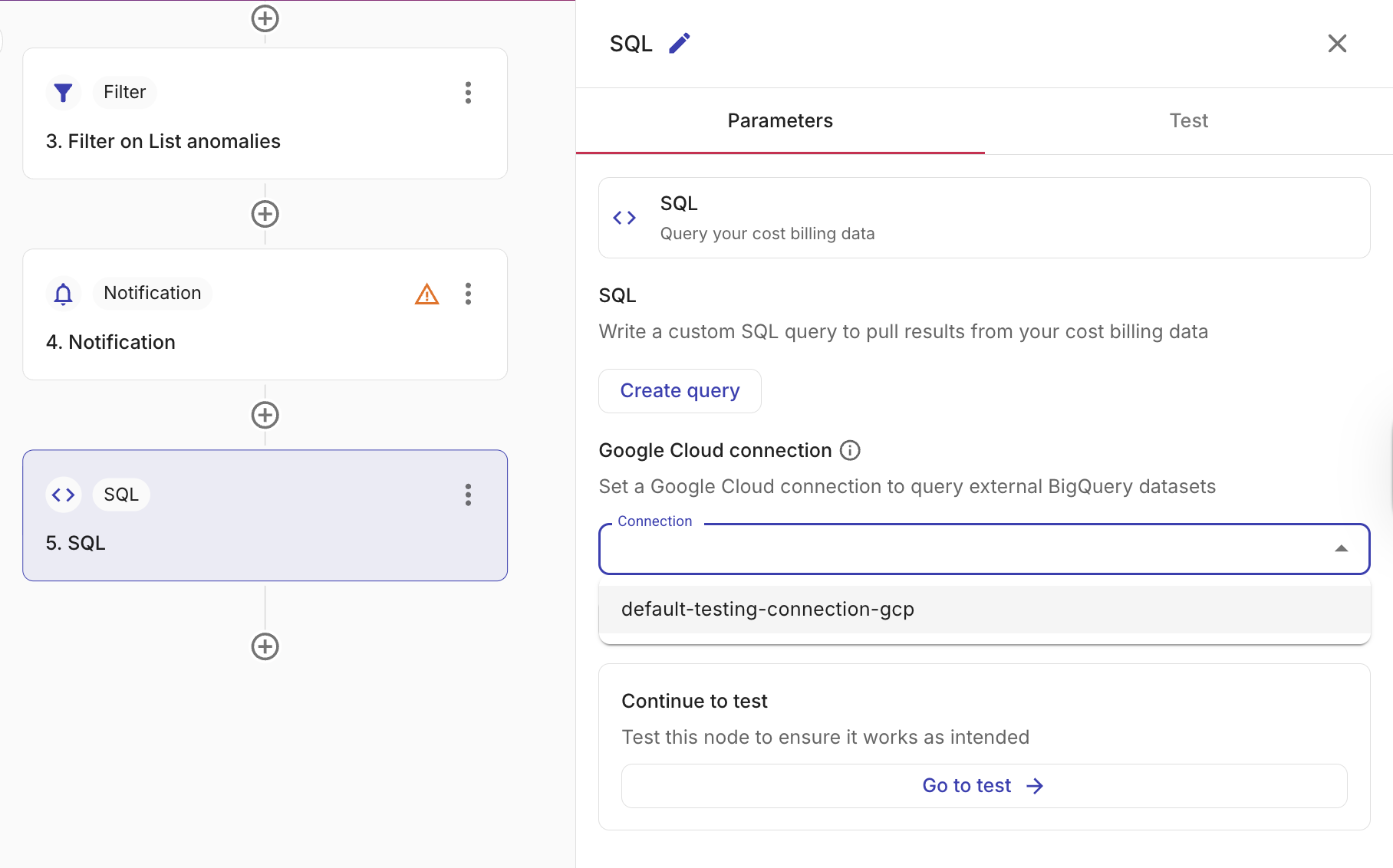
-
適切な connection が存在しない場合は、Create new を選択して新しい GCP connection を設定してください。
connection を選択すると、SQL ノードには接続された Google Cloud プロジェクト内のテーブルが、DoiT の請求データエイリアスと並んで含まれるようになります。
-
Create query を選択します。Create a SQL query ウィンドウの Query タブで、外部データセットに対して完全修飾テーブル名(例:
`my-project.my_dataset.my_table`)を使用してクエリを作成およびテストします。入力中に、DoiT Cloud Intelligence が SQL クエリを検証し、構文エラーやその他の問題の可能性を即座にハイライト表示します。ヒントFormat を使用して SQL を自動的にインデントおよび改行し、読みやすく編集しやすくしてください。
注意SQL クエリエディタは、入力中のクエリを自動的に下書きとして保存し、画面遷移時のデータ損失を防ぎます。下書きは 24 時間保存され、デバイス間で同期されません。Save を選択すると、フローへの変更が確定され、ローカルの下書きがクリアされます。下書きが期限切れになった場合、CloudFlow は最後に保存されたバージョンに戻ります。
-
Run query を選択してクエリをテストします。SQL ノードエディタでは、クエリが正常に実�行されることが、クエリを作成するための必須条件となっており、検証済みのクエリのみが作成されます。
テスト
ノードをテストするには、Test を選択してください。