Datastore ノード
Datastore ノードを使用すると、管理されたデータストア内に構造化データを保存・取得・更新・削除し、フロー内で利用できます。外部データベースに接続せずにフロー実行間で情報を永続化したい場合に便利です。たとえば、フローがすでに処理したクラウドリソースを記録したり、プロジェクト ID とその予算閾値のテーブルを保持したり、アカウントやリージョンごとにスケジュールされたフローが最後に実行された時刻を追跡する、といった用途です。作成したテーブルには、お客様の組織内のフローからのみアクセスできます。
テーブルの作成と管理
フローで Datastore ノードを使用する前に、データを保存するためのテーブルを 1 つ以上作成してください。CloudFlow のランディングページで Tables を選択し、テーブルを管理する Datastore タブを開きます。
テーブルを作成する
-
CloudFlow のランディングページで Tables を選択し、Datastore タブを開きます。
-
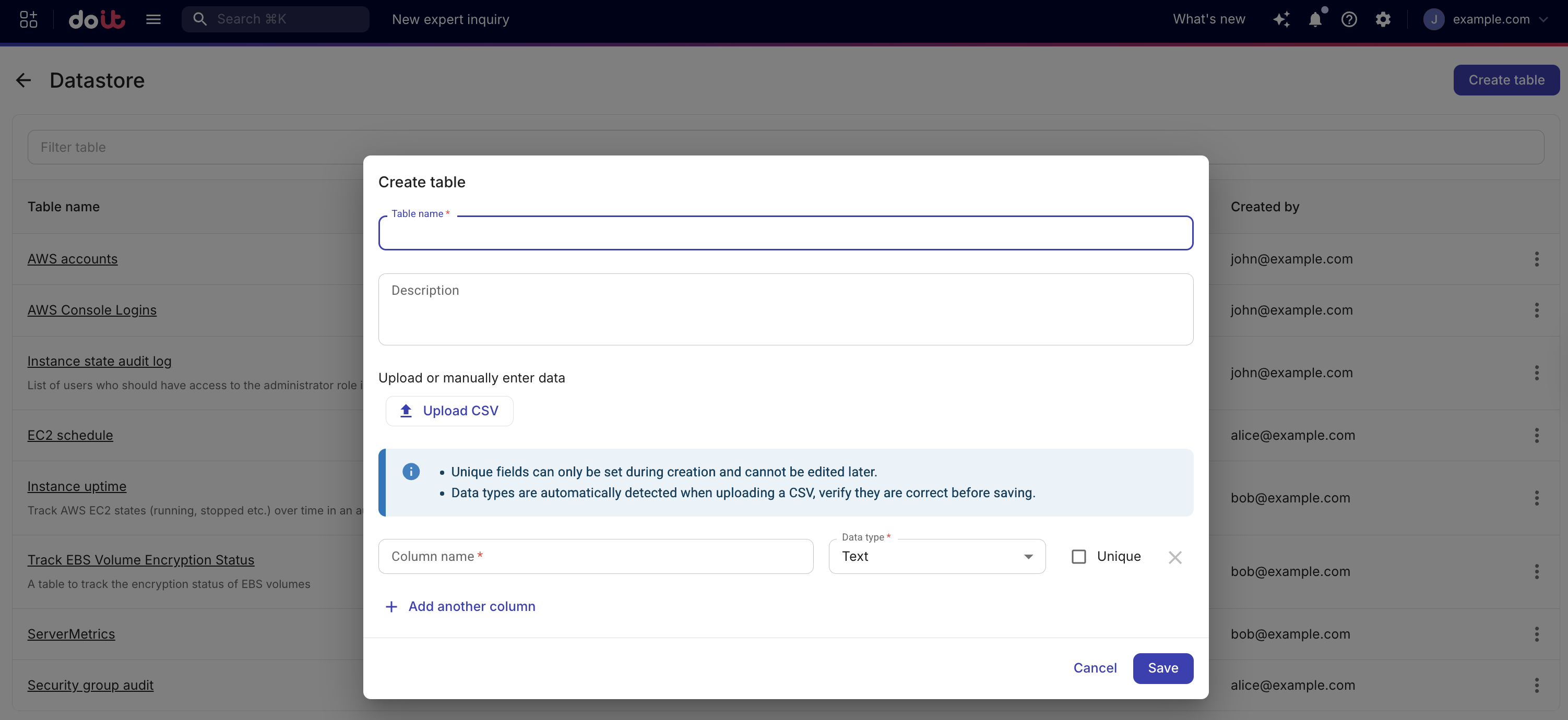
Create table を選択します。
-
Table name にテーブル名を入力します。テーブル名は作成後に変更できません。
-
(任意)Description に、そのテーブルが保存する内容の簡単な説明を入力します。
-
列を手動で定義するか、CSV ファイルをアップロードします。
-
Manually define columns: 1 つ以上の列を、名前とデータタイプとともに定義します。列を Unique としてマークすると、その列で同じ値を持つレコードが 2 つ存在しないように強制できます。Upsert アクションを使用する場合は、少なくとも 1 つの一意列が必要です。Upsert キーとして使用できるのは、一意列のみです。
-
CSV ingestion: Upload CSV を選択し、
.csvファイルを選択します。CSV ファイルには次の要件があります。-
最大ファイルサイズは 5 MB。
-
最大 50 列。
-
最大 5,000 行。
-
CSV ファイルは圧縮されていてはいけません(例: ZIP や GZ は不可)。
-
先頭行にヘッダー行を使用します。新しいテーブルでも列の順序は保持されます。
-
列名は、先頭が英字またはアンダースコアで始まり、その後に英数字またはアンダースコアを続ける必要があります。
-
列名の重複は不可。
-
CSV アップロード時に、列のデータタイプは自動検出されます。テーブルを保存する前に、正しいかを必ず確認してください。
-
日付およびタイムスタンプ値は RFC3339/ISO 8601 UTC format に従う必要があります(例: タイムスタンプは
YYYY-MM-DDTHH:MM:SSZ、日付のみのフィールドはYYYY-MM-DD)。
Save をクリックすると、まずテーブルが作成され、その後 CSV の行が挿入されます。挿入処理(たとえば無効なデータや接続問題が原因)が失敗した場合、テーブル自体はすでに存在しているものの行が 0 件の状態になり、エラーメッセージが表示されることがあります。CSV に機微情報や個人を特定できる情報(PII)が含まれる場合は、アップロード前に必ずマスキングやサニタイズを行ってください。
CSV の例(ヘッダー行とデータ行):
instance_id,state,last_updated
i-001,running,2026-01-15T10:00:00Z
i-002,stopped,2026-01-14T09:30:00Z -
-
-
Save を選択します。
テーブルを編集する
テーブルの説明を更新したり、列を追加または削除したりできます。テーブル名は作成後に変更できず、既存の列名やデータタイプも変更できません。
既存のテーブルを更新する目的では、CSV ingestion は使用できません。
-
テーブルの列構成を変更するには、Edit table を使用して列を追加または削除してください。
-
既存テーブルに行を追加するには、Datastore タブ内の Add row、または Datastore の Insert または Upsert ノードを含むフローを使用してください。
-
Datastore ブラウザから対象のテーブルを開きます。
-
Edit table を選択します。
-
必要な変更を行い、Save を選択します。
レコードの参照と管理
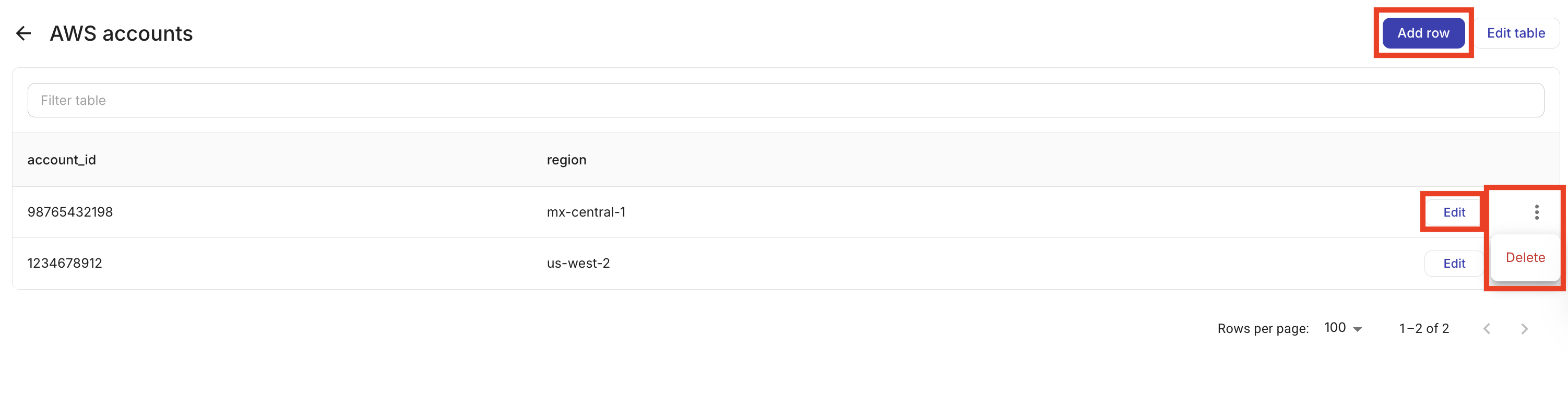
テーブルを開くと、そのテーブル内のレコードが表示されます。テーブルの詳細ビューから、次の操作ができます。
-
レコードの追加: Add row を選択し、列の値を入力します。
-
レコードの編集: 行を選択して、その値を更新します。
-
レコードの削除: 1 行以上を選択し、削除します。
レコードはページ分割され、任意の列でソートできます。
テーブルを削除する
テーブルを削除すると、そのテーブル内のすべてのレコードが完全に削除されます。テーブルが 1 つ以上のフローで使用されている場合でも削除可能です。コンソールは、そのテーブルを使用している公開済みフローをすべて unpublish し、ドラフトフローからはテーブル参照を削除します。これらのフローは、更新されるまで(たとえば別のテーブルを選択する、または Datastore ノードを削除するまで)実行時に失敗する可能性があります。フローの破損を防ぐには、そのテーブルを使用している各フローで、テーブル削除前に Datastore ノードを削除するか再設定してください。
テーブルを削除するには、Datastore タブで削除したいテーブル行の右端にあるケバブメニュー(⋮)を選択し、Delete を選択します。

アクション
フロー内で Datastore ノードを設定する際、+ ボタンを使ってパラメータに前段ノードの値を参照できます。詳しくは Node parameters を参照してください。次のいずれかのアクションを選択します。
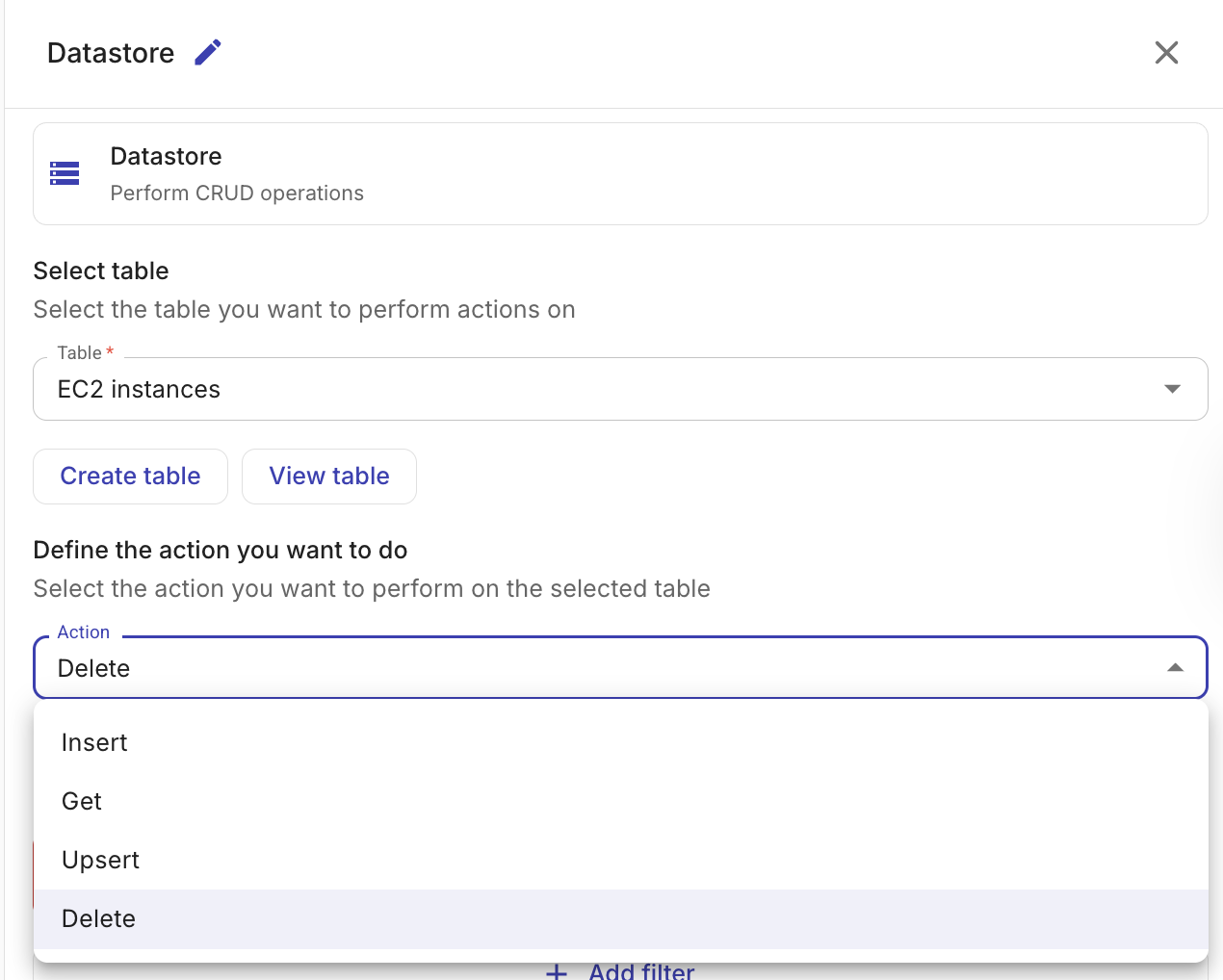
Get records
テーブルからレコードを取得します。返されるレコードと含めるデータを制御できます。
-
Table: クエリ対象のテーブル。
-
(任意)Columns: 結果に含める列を選択します。列を選択しない場合、すべての列が返されます。
-
(任意)Filters: 結果を絞り込む条件を定義します。1 つのフィルターグループ内の条件は AND ロジックで結合され、複数のフィルターグループは OR ロジックで結合されます。
使用できるフィルター演算子は次のとおりです。
Operator 説明 ==等しい !=等しくない >より大きい >=以上 <より小さい <=以下または等しい フィルター値には、フロー内の前段ノードの出力を参照できます。
-
(任意)Limit: 返されるレコードの最大数(1–5,000)。
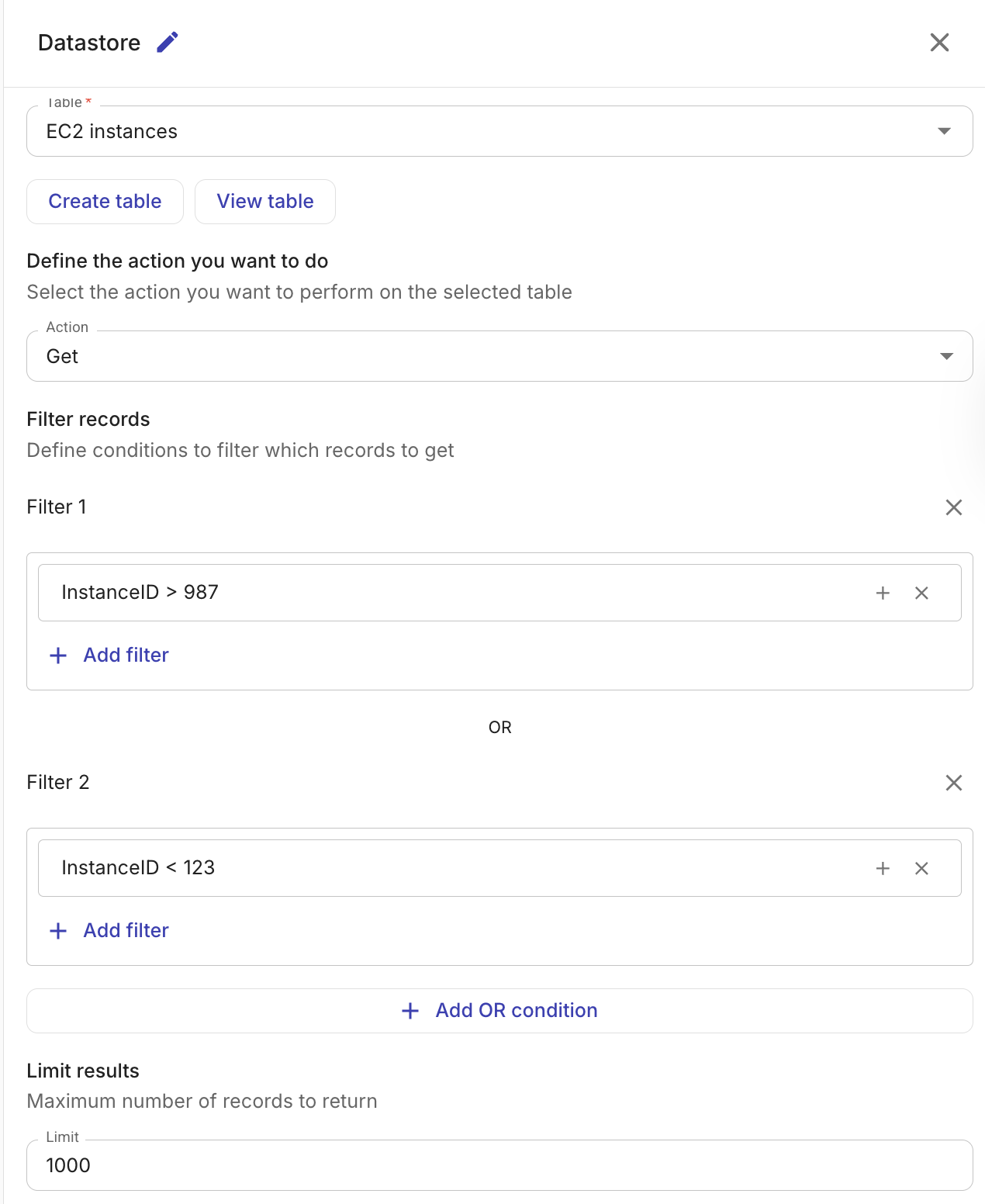
Get records アクションの出力は、条件に一致したレコードの配列であり、フロー内の後続ノードから参照できます。
Insert records
1 件以上のレコードをテーブルに挿入します。
-
Table: レコードを挿入するテーブル。
-
Column mappings: 各列に値をマッピングします。値は静的な値でも、前段ノードの出力参照でもかまいません。
前段ノードの出力が複数のアイテム(例: EC2 インスタンスのリスト)を含む場合、Datastore ノードはアイテムごとに 1 レコードを自動的に作成します。
レコードは最大 1,000 行ずつのバッチで挿入されます。挿入はバッチ単位でアトミックに行われ、バッチ内のいずれか 1 件でも検証に失敗した場合、そのバッチのレコードは 1 件も挿入されません。
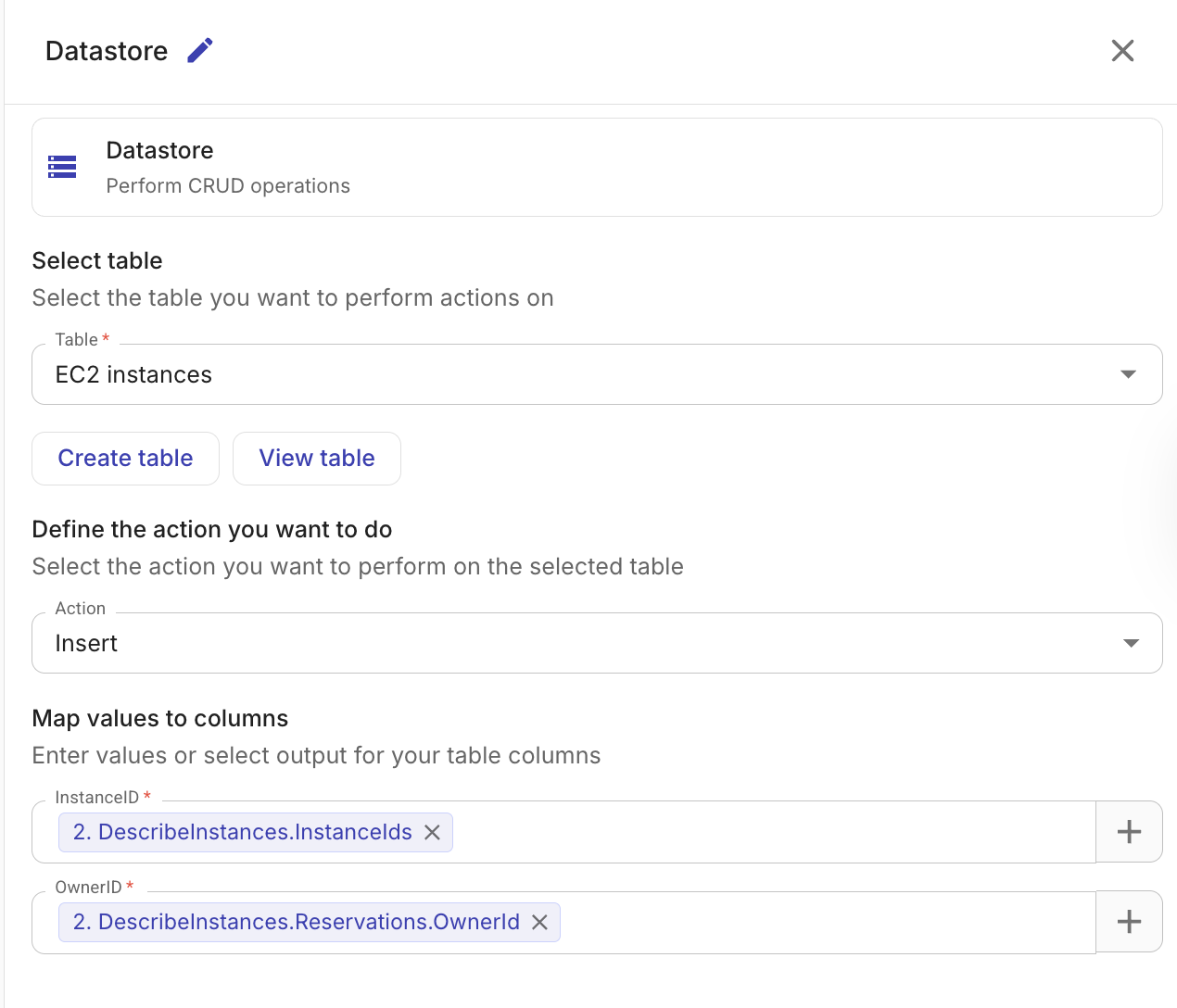
出力には、挿入されたレコードの ID と、挿入された合計行数が含まれます。
Upsert records
一意キー列に基づき、新規レコードの挿入または既存レコードの更新を行います。外部データソースとテーブルの内容を重複なく同期したい場合に有用です。
-
Table: Upsert 対象のテーブル。
-
Upsert key: レコードが既に存在するかどうかを判定する列です。同じキー値を持つレコードが存在する場合は更新され、存在しない場合は新しいレコードが挿入されます。Upsert キー列は、テーブル作成時に unique としてマークされている必要があります。
-
Column mappings: Insert records と同様に、各列に値をマッピングします。
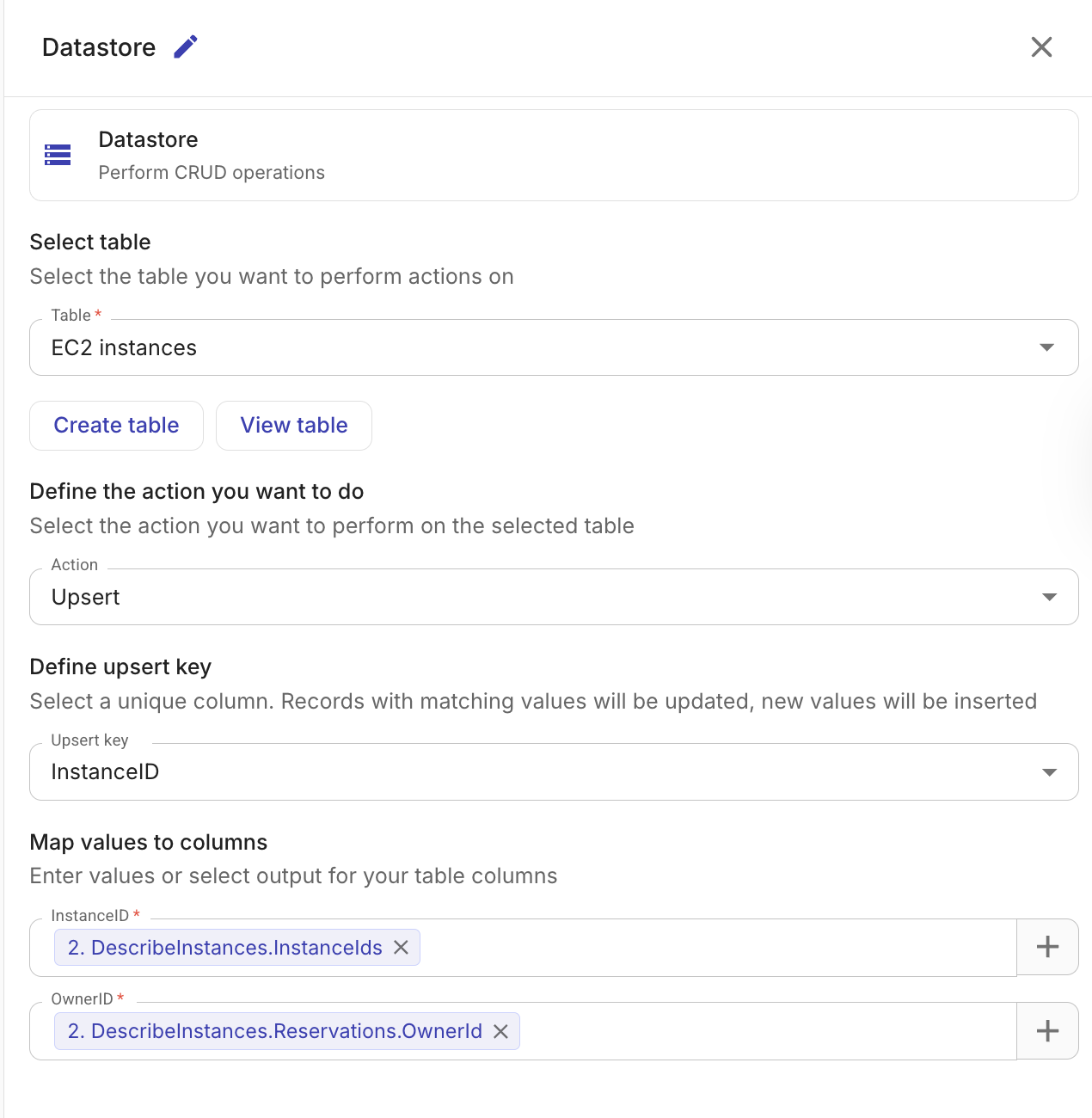
出力には、挿入および更新されたレコードの件数と ID が含まれます。
Delete records
指定�したフィルター条件に一致するレコードをテーブルから削除します。
-
Table: レコードを削除するテーブル。
-
Filters: 削除対象レコードを特定する条件を定義します。1 つのフィルターグループ内の条件は AND ロジックで結合され、複数のフィルターグループは OR ロジックで結合されます。誤ってテーブル全体を削除してしまうことを防ぐため、少なくとも 1 つのフィルター条件が必須です。
Get records と同じフィルター演算子
==,!=,>,>=,<,<=を利用できます。フィルター値には、フロー内の前段ノードの出力を参照できます。
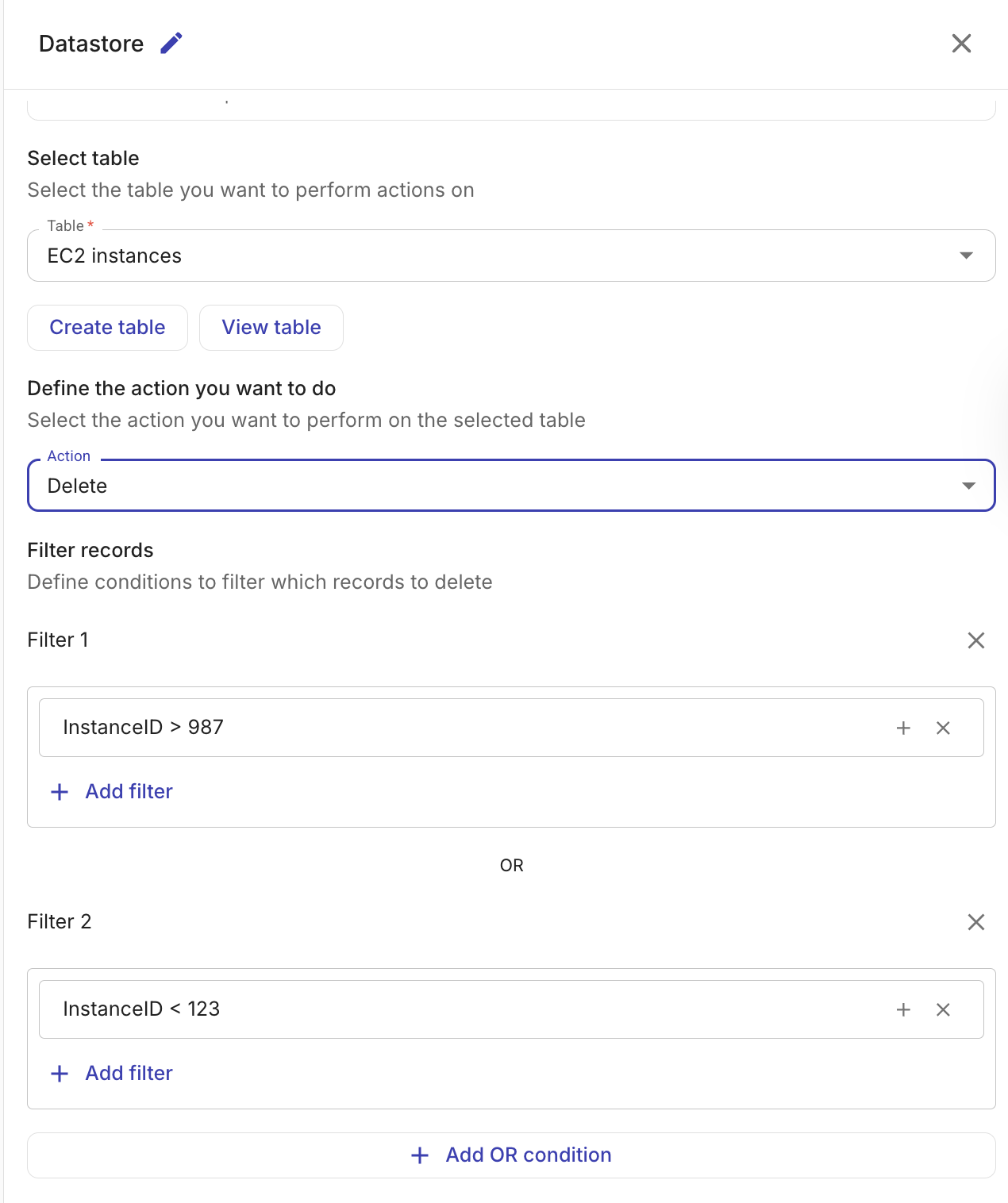
出力には、削除されたレコード数(deletedCount)とテーブル ID が含まれます。
サポートされる列タイプ
Datastore でテーブルを作成する際、次の列タイプを利用できます。
| Type | 説明 | 例 |
|---|---|---|
| Text | 可変長文字列 | us-east-1 |
| Integer | 整数値 | 42 |
| Numeric | 小数値 | 3.14 |
| Boolean | 真偽値 | true |
| Date | カレンダー日付 (yyyy-MM-dd) | 2026-01-15 |
| Timestamp | タイムゾーン付き日時 | 2026-01-15T10:30:00Z |
| JSON | 構造化された JSON データ | {"key": "value"} |
例:EC2 インスタンスの状態変更を追跡する
Datastore ノードの一般的なユースケースとして、クラウドリソースの状態を時間とともに追跡するルックアップテーブルを維持することがあります。例えば、次のようなフローを構築できます。
- AWS ノードを使用して EC2 インスタンスを一覧表示します。
- Datastore ノードで Upsert アクションを使用し、アップサートキーとしてインスタンス ID を使って、各インスタンスの現在の状態でテーブルを更新します。
- 2 つ目の Datastore ノードで Get records アクションを使用し、7 日以上停止しているインスタンスをテーブルからクエリします。
- 長期間停止しているインスタンスの一覧を含めて、該当チームに Notification を送信します。
Upsert アクションは重複を作成するのではなく既存のレコードを更新するため、テーブルには常に各インスタンスの最新の状態が反映されます。
テスト
ノードをテストするには、Test を選択してください。