Datastore node
A Datastore node lets you store, retrieve, update, and delete structured data within your flows using a managed data store. It is useful when you need to persist information across flow runs without connecting to an external database — for example, to remember which cloud resources a flow has already processed, to keep a table of project IDs and their budget thresholds, or to track the last time a scheduled flow ran per account or region. The tables you create are only accessible to flows within your organization.
Create and manage tables
Before using a Datastore node in a flow, create one or more tables to store your data. On the CloudFlow landing page, select Tables to open the Datastore tab, where you manage your tables.
Create a table
-
On the CloudFlow landing page, select Tables to open the Datastore tab.
-
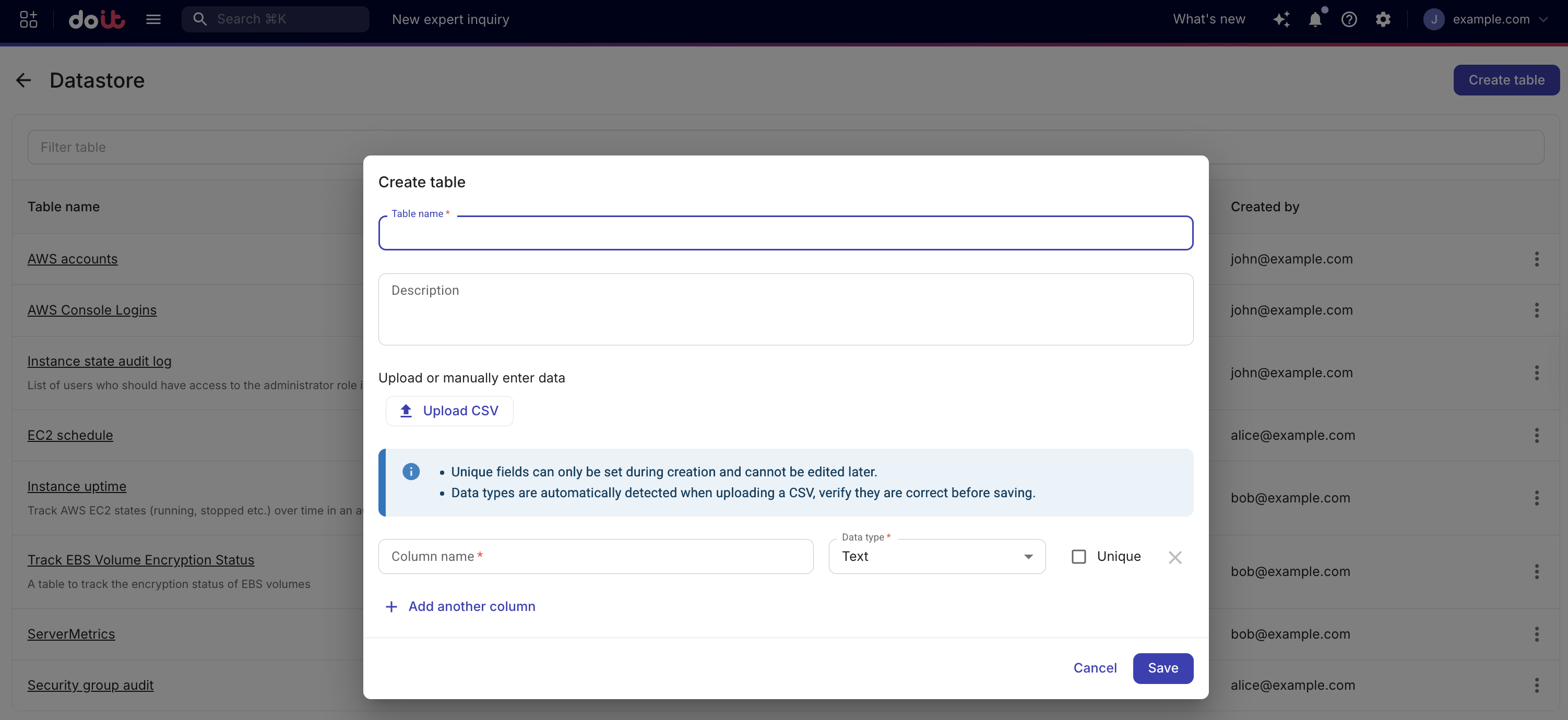
Select Create table.
-
In Table name, enter a name for the table. The table name cannot be changed after creation.
-
(Optional) In Description, enter a brief description of what the table stores.
-
Either define columns manually or upload a CSV file.
-
Manually define columns: Define one or more columns, each with a name and data type. You can mark a column as Unique to enforce that no two records share the same value in that column. At least one unique column is required if you plan to use the Upsert action, because only unique columns can serve as upsert keys.
-
CSV ingestion: Select Upload CSV and choose a
.csvfile. The CSV file requirements are:-
Maximum 5 MB file size.
-
Maximum 50 columns.
-
Maximum 5,000 rows.
-
The CSV file cannot be compressed (for example, no ZIP or GZ).
-
Use a header row as the first line. The order of the columns is preserved in the new table.
-
Column names must start with a letter or underscore, followed by alphanumeric or underscore.
-
No duplicate column names.
-
Column data types are automatically detected when uploading the CSV. You must verify they are correct before saving the table.
-
Date and timestamp values must follow RFC3339/ISO 8601 UTC format (for example,
YYYY-MM-DDTHH:MM:SSZfor timestamps, orYYYY-MM-DDfor date-only fields).
When you click Save, the table is created first and then the CSV rows are inserted. If that insert step fails (for example, due to invalid data or a connection problem), the table may already exist but contain no rows, and an error message is shown. If your CSV contains sensitive or personally identifiable information (PII), sanitize or mask it before uploading.
Example CSV (header row plus data rows):
instance_id,state,last_updated
i-001,running,2026-01-15T10:00:00Z
i-002,stopped,2026-01-14T09:30:00Z -
-
-
Select Save.
Edit a table
You can update a table's description and add or remove columns. The table name cannot be changed after creation, and existing columns cannot be renamed or have their data type changed.
You cannot use CSV ingestion to update an existing table.
-
To change which columns a table has, use Edit table and add or remove columns.
-
To add more rows to an existing table, use Add row in the Datastore tab or a flow with a Datastore Insert or Upsert node.
-
Open the table from the Datastore browser.
-
Select Edit table.
-
Make your changes and select Save.
Browse and manage records
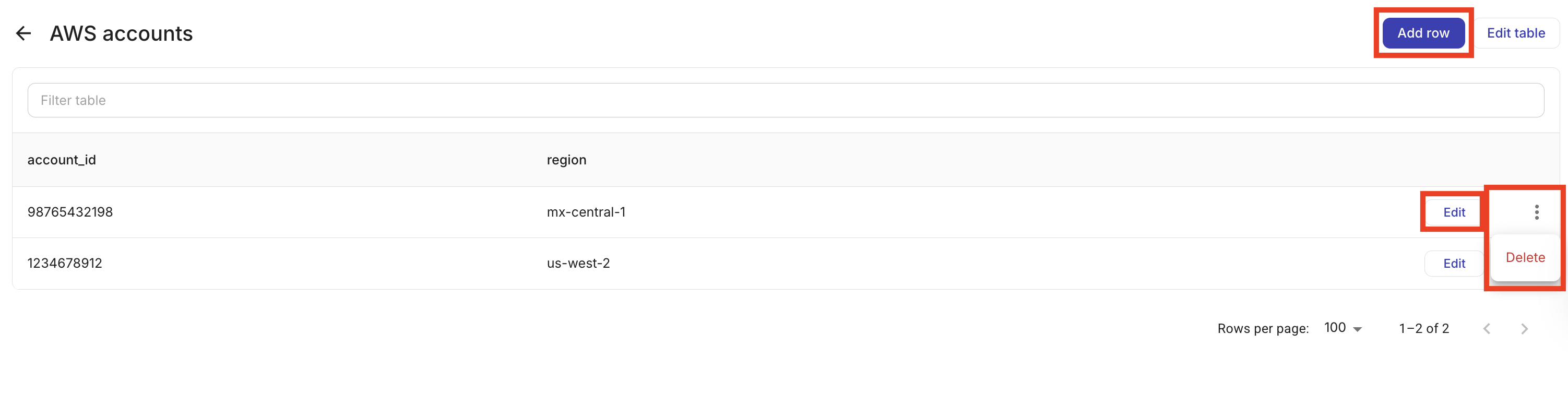
Open a table to view its records. From the table detail view, you can:
-
Add a record: Select Add row and fill in the column values.
-
Edit a record: Select a row to update its values.
-
Delete records: Select one or more rows and delete them.
Records are paginated and sortable by any column.
Delete a table
Deleting a table permanently removes all of its records. If the table is used in one or more flows, you can still delete it. The console will unpublish any published flows that use the table and remove the table from draft flows. Those flows may fail when run until you update them (for example, by choosing a different table or removing the Datastore node). To avoid broken flows, remove or reconfigure the Datastore node in each flow that uses the table before deleting the table.
To delete a table, from the Datastore tab, select the kebab menu (⋮) at the rightmost end of the table that you want to delete and select Delete.

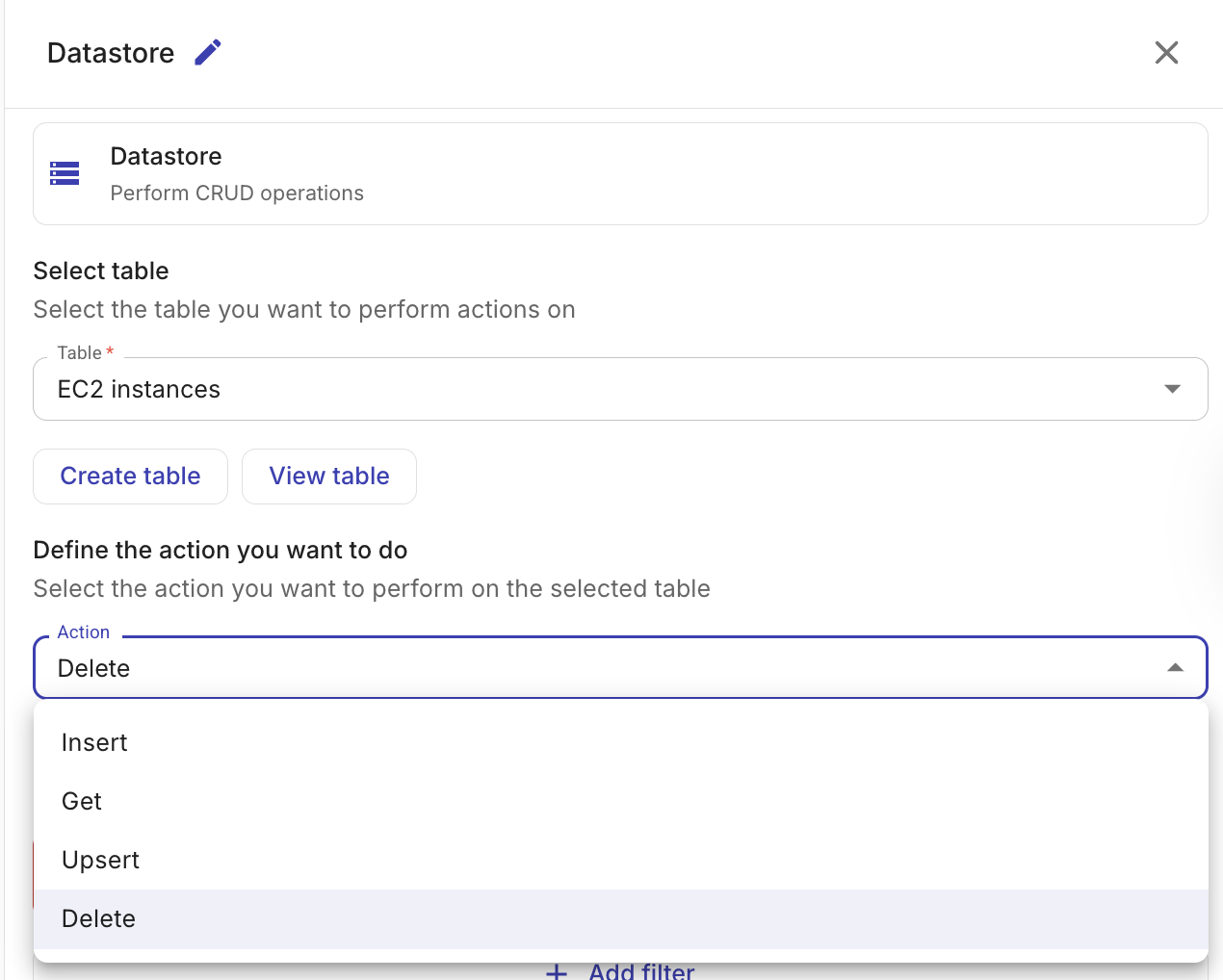
Actions
When configuring a Datastore node in a flow, you can reference values from previous nodes in parameters using the + button; see Node parameters. Select one of the following actions:
Get records
Retrieves records from a table. You can control which records are returned and what data is included:
-
Table: The table to query.
-
(Optional) Columns: Select specific columns to include in the result. If no columns are selected, all columns are returned.
-
(Optional) Filters: Define conditions to narrow down the results. Conditions within a filter group are combined with AND logic. Multiple filter groups are combined with OR logic.
The following filter operators are available:
Operator Description ==Equal to !=Not equal to >Greater than >=Greater than or equal to <Less than <=Less than or equal to Filter values can reference output from previous nodes in the flow.
-
(Optional) Limit: The maximum number of records to return (1–5,000).
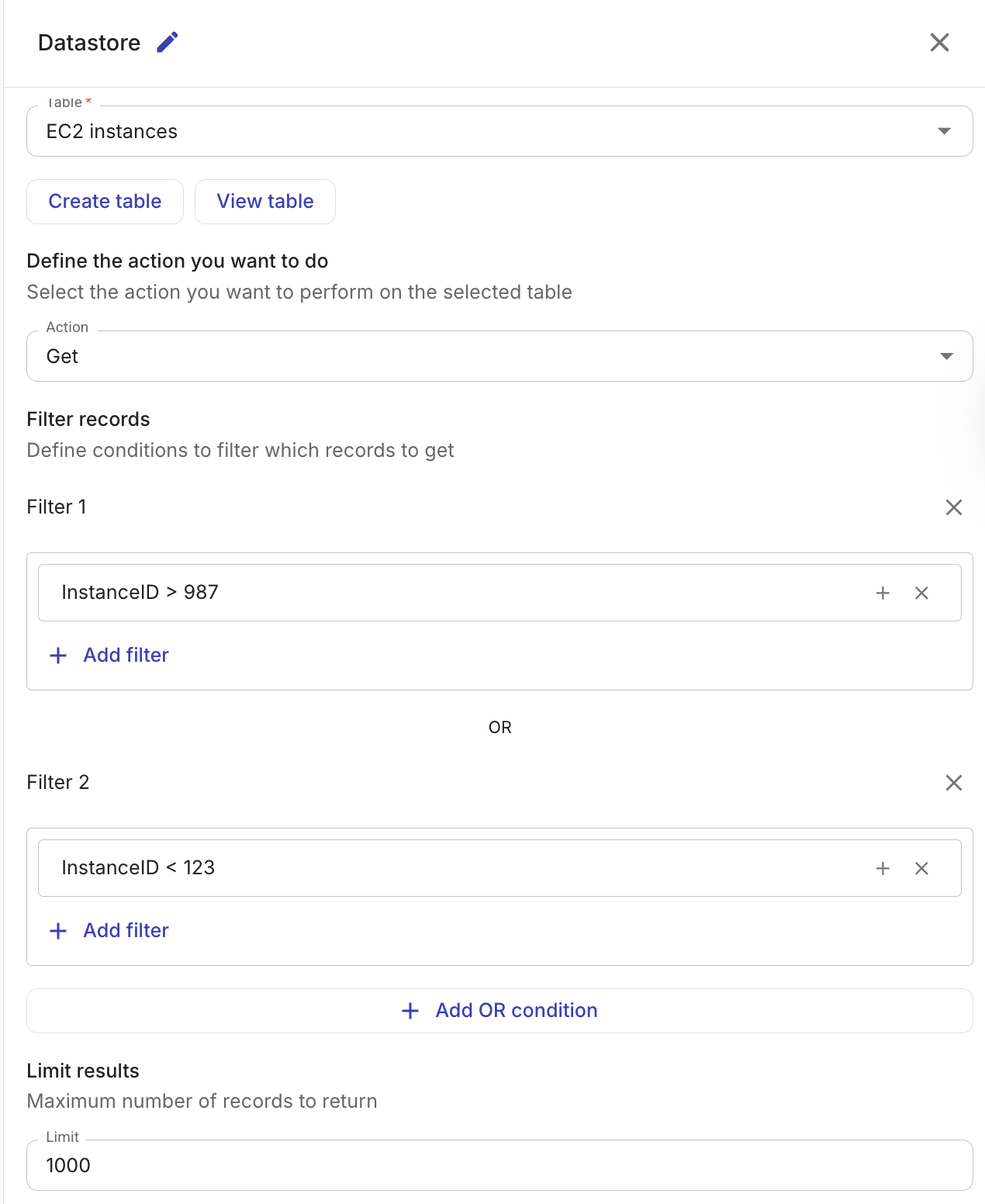
The output of the Get records action is an array of matching records, which subsequent nodes in the flow can reference.
Insert records
Inserts one or more records into a table.
-
Table: The table to insert records into.
-
Column mappings: Map each column to a value. Values can be static or reference output from previous nodes.
When a previous node's output contains multiple items (for example, a list of EC2 instances), the Datastore node automatically creates one record per item.
Records are inserted in batches of up to 1,000 rows. The insertion is atomic per batch — if any record in a batch fails validation, none of the records in that batch are inserted.
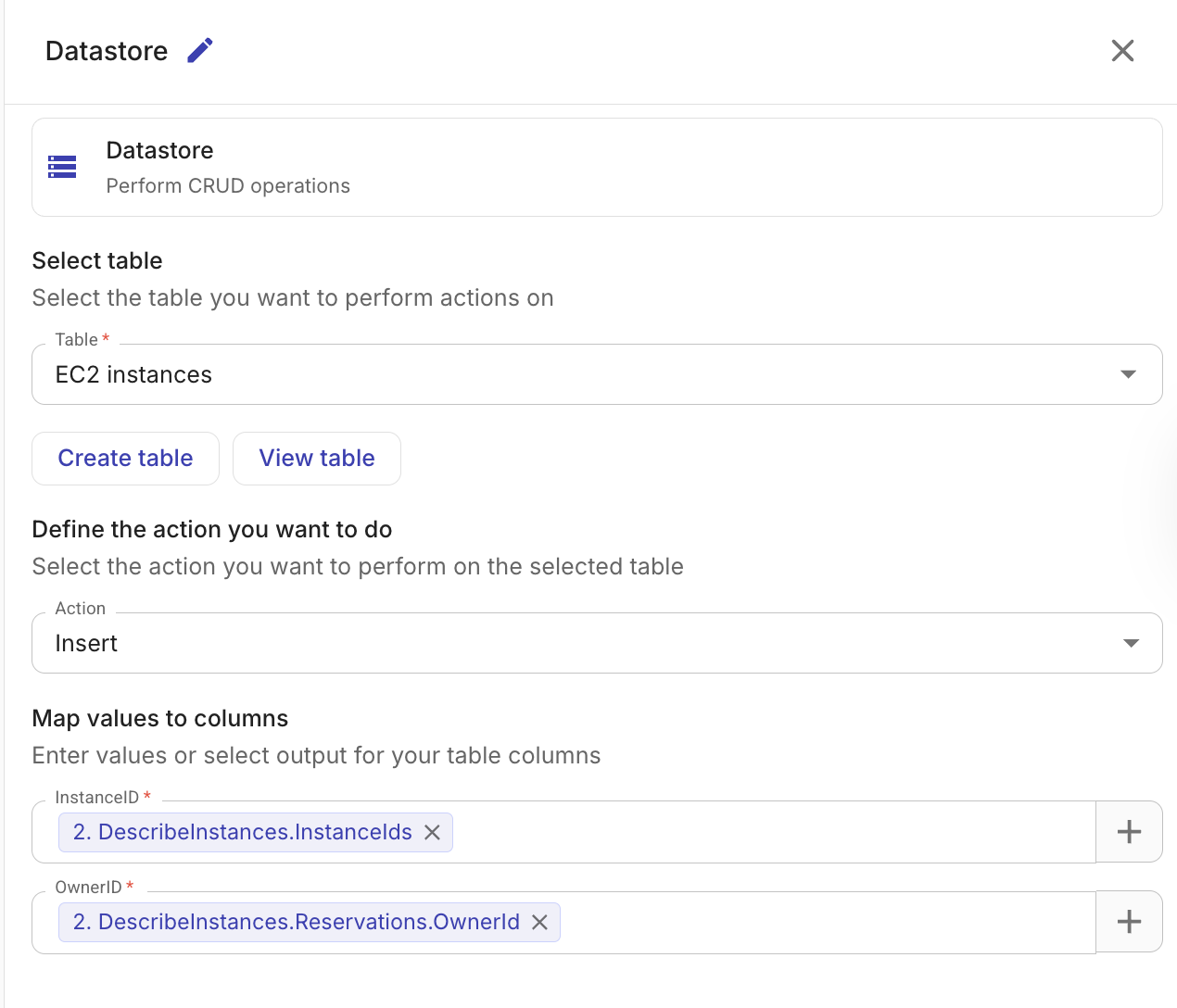
The output includes the IDs of the inserted records and a count of the total rows inserted.
Upsert records
Inserts new records or updates existing ones based on a unique key column. This is useful when you want to keep a table in sync with an external data source without creating duplicates.
-
Table: The table to upsert records into.
-
Upsert key: The column used to determine whether a record already exists. If a record with the same key value exists, it is updated; otherwise, a new record is inserted. The upsert key column should be marked as unique when creating the table.
-
Column mappings: Map each column to a value, the same as with Insert records.
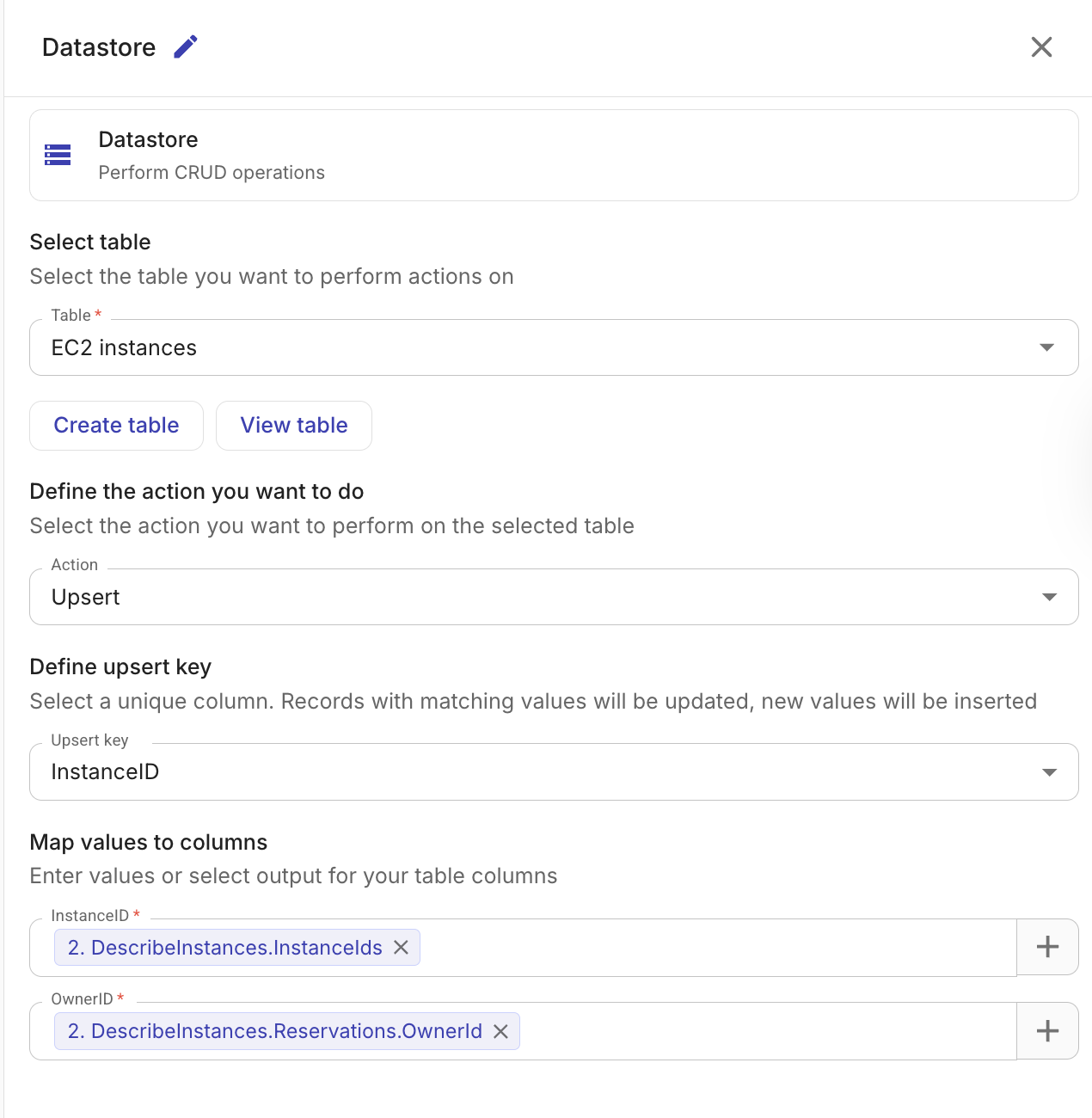
The output includes counts and IDs for both inserted and updated records.
Delete records
Deletes records from a table that match the given filter conditions.
-
Table: The table from which to delete records.
-
Filters: Define conditions that identify which records to delete. Conditions within a filter group are combined with AND logic. Multiple filter groups are combined with OR logic. At least one filter condition is required to avoid accidental full-table deletes.
The same filter operators are available as for Get records:
==,!=,>,>=,<,<=. Filter values can reference output from previous nodes in the flow.
The output includes the number of records deleted (deletedCount) and the table ID.
Supported column types
When creating a table in the Datastore, the following column types are available:
| Type | Description | Example |
|---|---|---|
| Text | Variable-length string | us-east-1 |
| Integer | Whole number | 42 |
| Numeric | Decimal number | 3.14 |
| Boolean | True or false | true |
| Date | Calendar date (yyyy-MM-dd) | 2026-01-15 |
| Timestamp | Date and time with timezone | 2026-01-15T10:30:00Z |
| JSON | Structured JSON data | {"key": "value"} |
Example: Track EC2 instance state changes
A common use case for the Datastore node is to maintain a lookup table that tracks cloud resource state over time. For example, you could build a flow that:
- Uses an AWS node to list EC2 instances.
- Uses an Upsert action on the Datastore node to update a table with the current state of each instance, using the instance ID as the upsert key.
- Uses a Get records action on a second Datastore node to query the table for instances that have been stopped for more than 7 days.
- Sends a Notification to the relevant team with the list of long-stopped instances.
Since the upsert action updates existing records instead of creating duplicates, the table always reflects the latest state of each instance.
Test
Select Test to test the node.