Sub Flow ノード
Sub Flow ノードを使用すると、自分のフローの中から別のフローを呼び出すことができます。呼び出されるフロー自体は通常のフローであり、Sub Flow ノードから呼び出されたときにのみサブフローとして動作します。共有ロジックの再利用、複雑なフローの分割、あるいは 1 つの親フローから複数のフローをオーケストレーションすることができます。例えば、親フローでどのクラウドアカウントや地域を対象にするかを決定し、その対象に対して同じクリーンアップ処理やコンプライアンスチェックを行うサブフローを呼び出すことで、アカウントごとにロジックを複製するのではなく 1 つのサブフローを維持できます。サブフローは現在のフローの子として実行され、その出力は後続のノードから利用できます。
親フローとサブフローの両方がスケジュールトリガーを使用している場合、サブフロー側のスケジュールは無視されます。��親フローがトリガーされると、サブフロー側のスケジュール設定に関係なく、Sub Flow ノードに到達した時点でサブフローがただちに呼び出されます。別のフローから呼び出される場合、サブフロー側のスケジュールを無効化する必要はありません。
Input and output
Input: サブフローは、Sub Flow ノードで設定した値を通じて、親フローから入力を受け取ります。親フローが実行されると、それらの値はサブフロー内のローカル変数として渡されるため、サブフロー内のノードは他のフローバリアブルと同様にそれらを利用できます。
Output: Flow output ノード がない場合、サブフローは executionId 以外に親フローへ返す出力データを持ちません。サブフロー内に Flow output ノードを追加して、名前付きの出力 (例えば、複数のフィールドや特定の構造) を公開してください。親フローは + ボタンやフィールドピッカーを通じてそれらの出力を参照できます。親フロー内の後続ノードは、Sub Flow ノードの出力を他のノード出力と同様に使用できます。
Sub Flow ノードの設定
-
呼び出したいサブフローを作成します。そのフロー内で、サブフローが呼び出される際に親フローから渡したい値ごとにローカル変数を作成します。これらは Sub Flow ノードを設定する前にサブフロー側で定義しておく必要があります。これらのローカル変数が親フロー側の Sub Flow ノードにおける実行パラメータとなるため、定義されていない場合、親フローが渡せるものが存在しません。
親フロー側で、これらのパラメータに値を設定することは任意です。親フローは、Sub Flow ノードの設定時にサブフローの任意のローカル変数へ値を設定できます。サブフローを作成して公開し、親フローの Sub Flow ノードで選択できるようにしてください。公開されていない場合、親フローが Sub Flow ノードに到達したときに CloudFlow はエラーをスローします。
-
親フローに Sub Flow ノードを追加します。
-
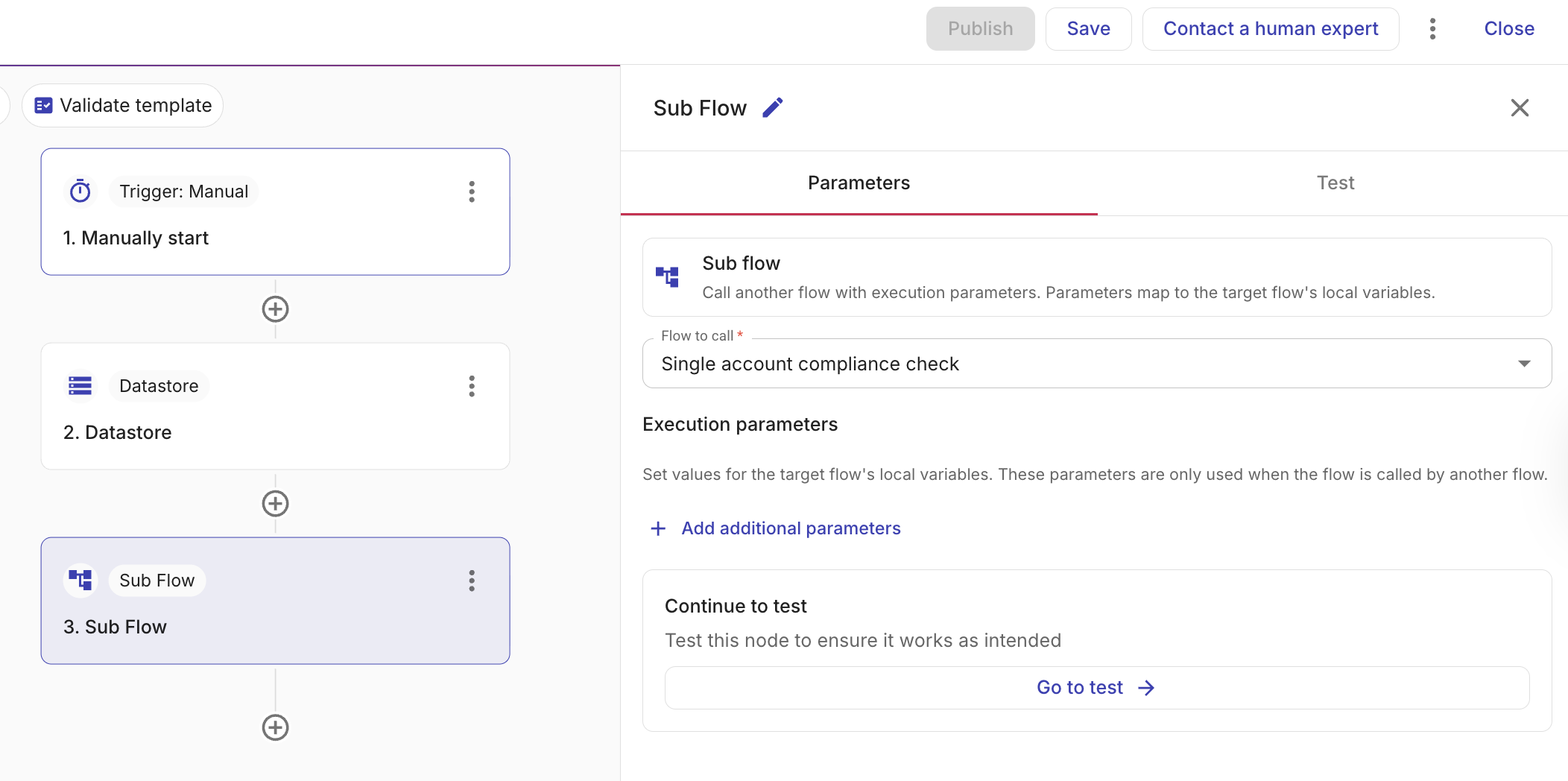
Flow to call で、呼び出したいサブフローを選択します。
-
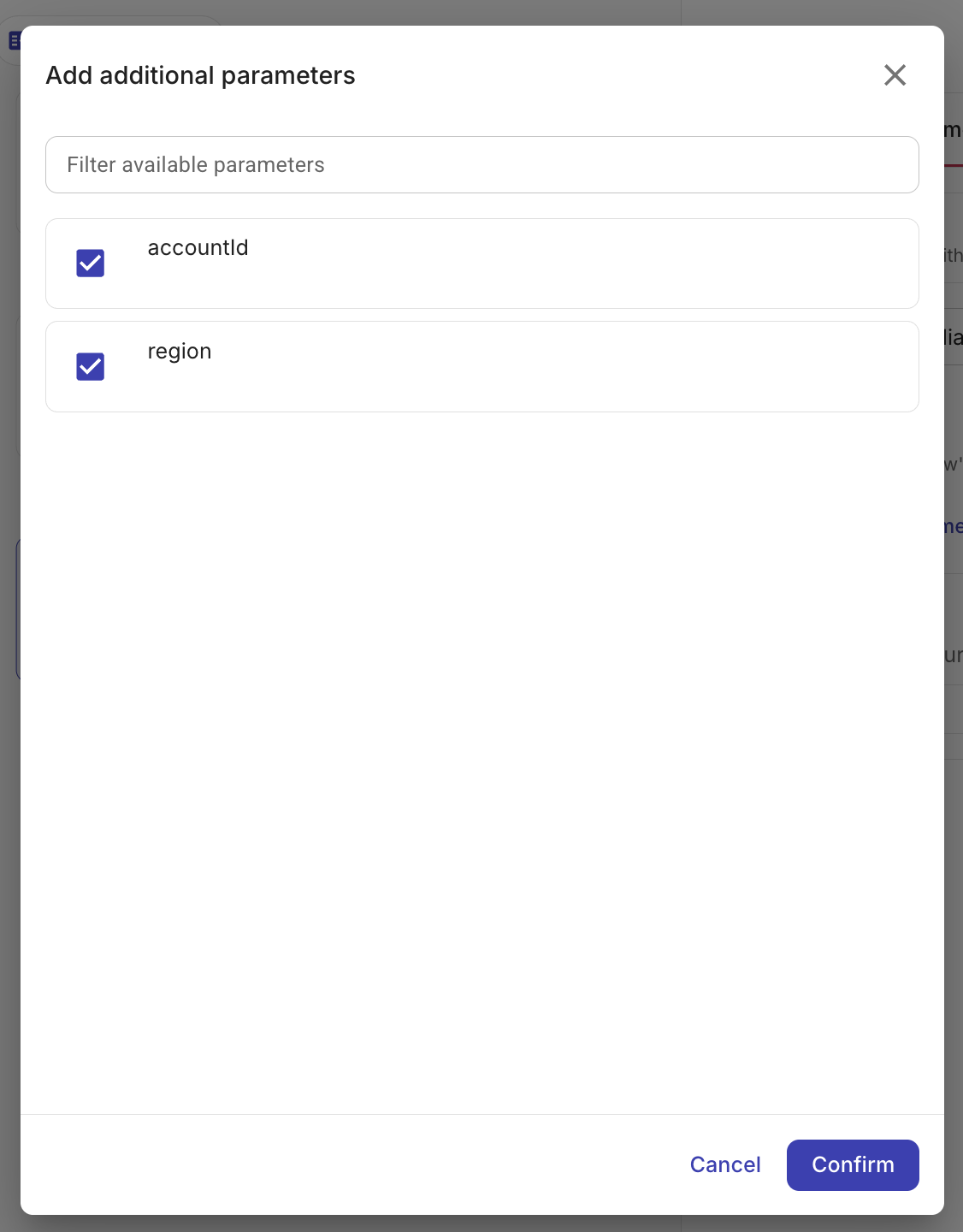
Flow to call でフローを選択した後、+Add additional parameters を選択して、サブフローに渡したいパラメータを追加します。これらはサブフローのローカル変数 (ステップ 1 でそのフロー内に定義したもの) です。
各パラメータに対して、親フロー側から値を設定します (例えば、直前のノードの出力や、親フローのローカル変数/グローバル変数から設定)。
CloudFlow は、親フローの実行時にそれらの値をサブフローへ渡します。サブフローは、別のフローから呼び出された場合にのみこれらのパラメータを使用します。サブフローが単体で実行される場合 (例えば、独自のトリガーや手動実行による場合)、その実行内でこれらの変数を設定し、親フローからの値は使用しません。
親フローが実行されると、選択したフローがサブフローとして実行されます。サブフローは親実行のコンテキスト内で実行されるため、データを渡し、サブフローの結果を親フロー内の後続ノードで利用できます。この結果がサブフローの出力となります (Input and output を参照)。
Sub flow run history
親フローの実行履歴では、各 Sub Flow ノードの実行に対応するサブフロー実行へのリンクが含まれているため、子実行を開いてそのステップ、出力、タイミングを確認できます。
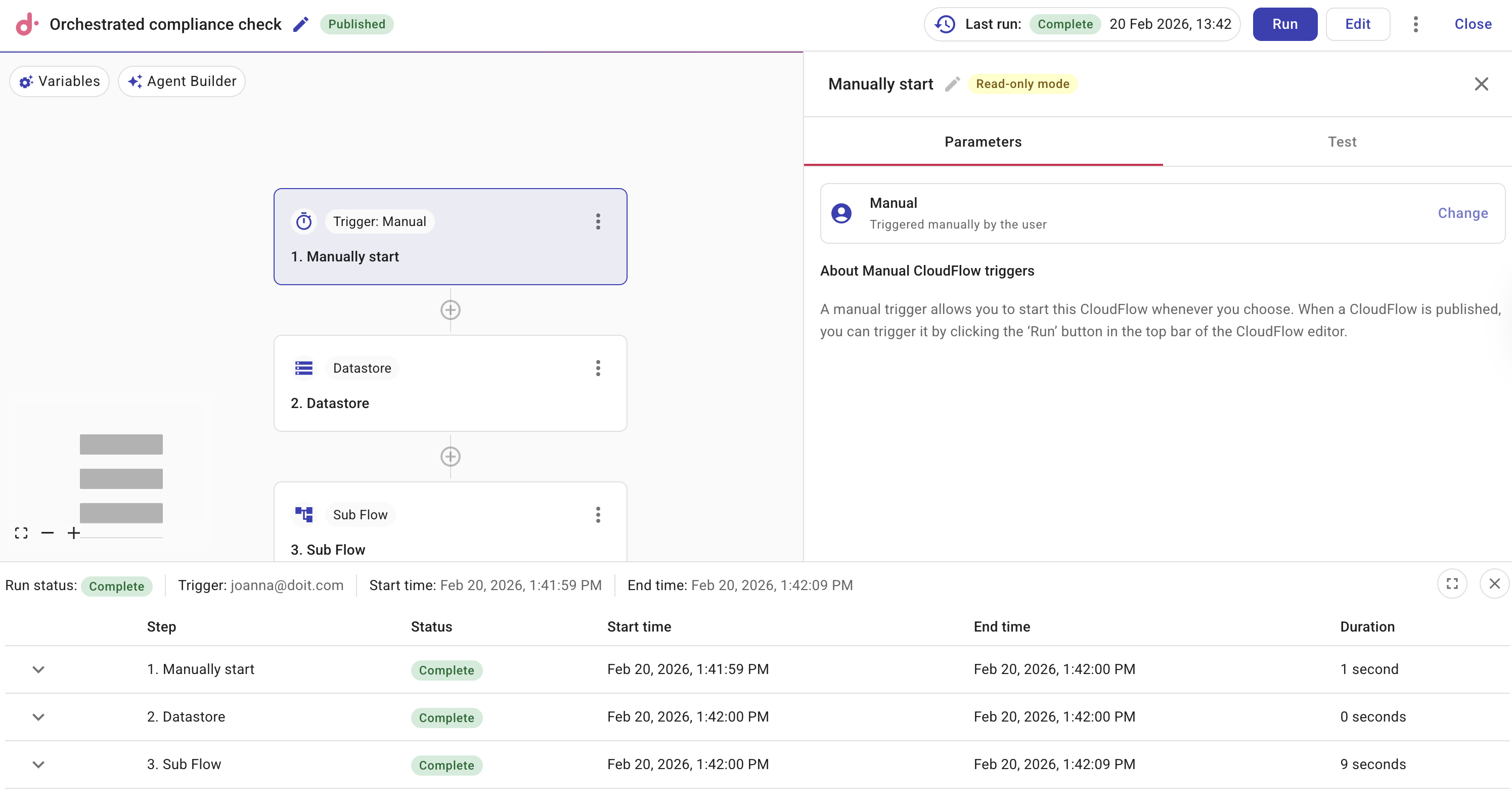
View subflow run を選択して、サブフローの実行履歴を表示します。
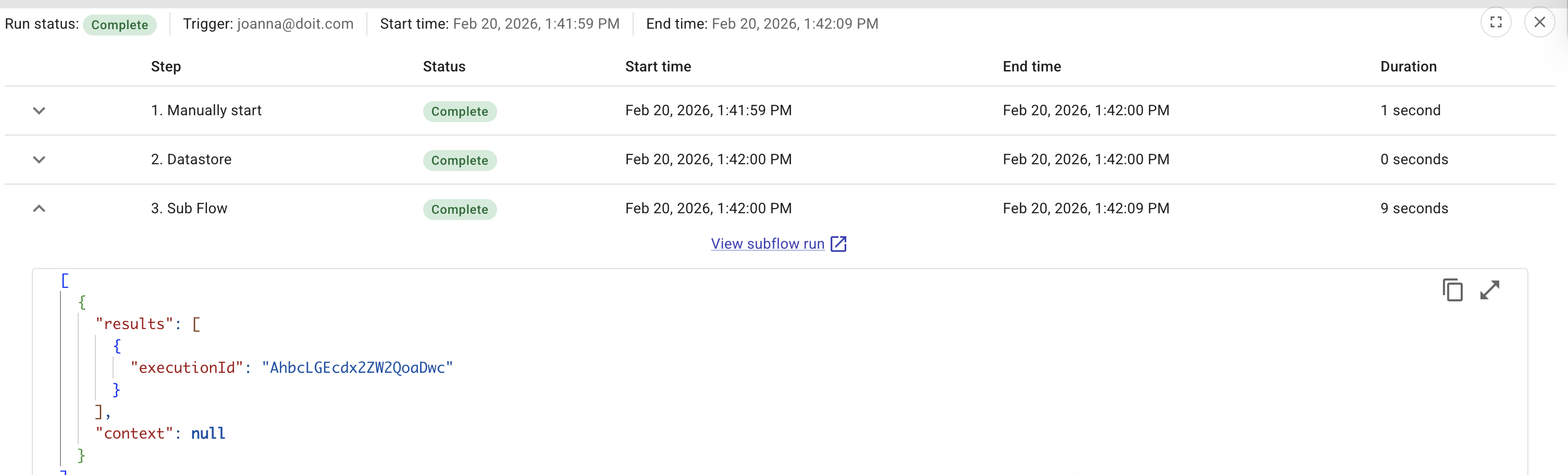
サブフローが失敗した場合、親フローは Sub Flow ノードで失敗します。親フローの実行履歴では、そのノードに表示されるエラーはサブフロー内で失敗したノードのエラー内容 (どのノードが、なぜ失敗したか) と同一であるため、サブフロー実行を開かなくても何が問題だったのかを把握できます。完全な履歴を確認したい場合は View subflow run を選択してください。
サブフロー内の承認
サブフロー内に承認が必要なノードが含まれている場合 (例えば、Require approval for this action が有効になっている AWS ノード や GCP ノード など)、親フローは Sub Flow ノードで承認が完了するまで一時停止します。
承認者が承認するとサブフローの実行が続行され、サブフローが終了すると親フローは自動的に再開されます。その後、親フローはサブフローの出力を受け取り、次のノードへ進みます。
承認者がアクションを拒否した場合、または承認がタイムアウトした場合、その結果は親フローへ伝播され、親フローは Sub Flow ノードで失敗します。実行履歴には、承認の拒否またはタイムアウトのエラーが表示されます。
例: オーケストレーションされたコンプライアンスチェック
以下の設計では、親フローが再利用可能なサブフローを呼び出して 1 つのアカウントを評価することで、週次のコンプライアンスチェックを実行します。サブフローは、独自のパラメータを用いて単体でも実行できます (例えば、単一アカウントに対する手動実行)。
親フロー: 週次コンプライアンスオーケストレーション
- Schedule トリガー: フローを毎週実行しま��す (例えば、毎週月曜日)。
- Datastore ノード: コンフィグテーブルからチェック対象のアカウント ID および地域を読み込みます (例えば、週次実行に含めるアカウントの一覧)。単一アカウント構成の場合は、固定値や 1 つのアカウントを返す Code ノードでも構いません。
- Sub Flow ノード: サブフロー Single-account compliance check を呼び出し、直前のノードから取得したアカウント ID と地域を実行パラメータとして渡します。
- Branch ノード: サブフローの出力を評価します (例えば、違反件数)。違反がある場合のパスと、アカウントがコンプライアンス準拠である場合のパスを分岐します。
- Notification ノード: Slack やメールにサマリーを送信します (例えば、Compliance check completed for account X: 3 violations や No issues found)。
サブフロー: 単一アカウントのコンプライアンスチェック
サブフローはローカル変数 accountId と region を定義します。親フローから呼び出される場合、Sub Flow ノードがこれらを渡します。サブフローが単体で実行される場合 (手動実行や独自トリガーによる場合) は、その実行でこれらの値を手動設定します。
- AWS ノード (または GCP ノード): 指定されたアカウントと地域内のリソースを一覧取得します (例えば、S3 buckets や EC2 instances)。フローのローカル変数
accountIdとregionを使用するようにノードを設定します。フローが単体で動作する場合も親フローから呼び出される場合も、ノードはこれらの変数を使用するように設定し、単に値の出どころが異なるだけです (単体実行時はその実行、サブフローとして呼び出される場合は親フロー)。 - Filter ノード: チェック対象となるリソースに絞り込みます (例えば、特定のタグが付与されていない buckets や、特定の状態にある instances など)。
- Policy ノード: 絞り込んだリソースをポリシーに対して評価します (例えば、「S3 buckets には cost-allocation タグが付与されている必要がある」など)。
- Transform ノード: ポリシー結果からサマリーを作成します (例えば、違反件数やリソース ID の一覧)。
- Flow output ノード: サマリーを公開します (例えば、違反件数)。これにより親フローがサマリーを利用できます。このノードがない場合、サブフローは executionId 以外に親フローへ返す出力データを持ちません。
その後、親フローは Branch ノードと Notification ノードでこのサマリーを使用します。Single-account compliance check は、他の親フロー (例えば異なるスケジュールやトリガーを持つフロー) からも、コンプライアンスロジックを複製することなく再利用できます。