レポートを作成する
Ava(当社の AI アシスタント) を利用する場合も、利用しない�場合も、ゼロから新しいレポートを作成できます。また、既存のレポートを基に作成することもできます。
必要な権限
- Cloud Analytics User
ゼロからレポートを作成する
ゼロから新しいレポートを作成するには、次の手順に従ってください。
-
DoiT コンソール にサインインし、上部ナビゲーションのメガメニューから レポートと分析 を選択し、レポート を選択します。
-
レポートを作成 を選択します。
ヒント- デフォルトビュー を設定している場合、新しいレポートは事前入力された設定から開始します。
- 一部の設定オプションは、Compact モード では異なる場所にあります。
レポートを直接設定し始めることも、Cloud Analytics copilot を使用することもできます。copilot を使用する場合に何が起こるかについては、次のセクションで説明します。
copilot でレポートを生成する
-
copilot のプロンプトで、レポートの目的を記述するか、提案されたプロンプトのいずれかを選択します。
-
(任意)追加情報を提供するには コンテキストを追加する を選択します。サポートされている任意の ディメンション・ラベル・タグ を選択できます。
-
Enter キーを押すか、送信ボタンを選択します。
copilot は、目的に最も適したレポート設定の生成を開始します。プロンプトフィールド内の停止アイコンまたは再生アイコンを選択することで、いつでも処理を停止または再開できます。
copilot が設定を完了するとレポートがレンダリングされ、それに応じてレポート設定が更新されます。
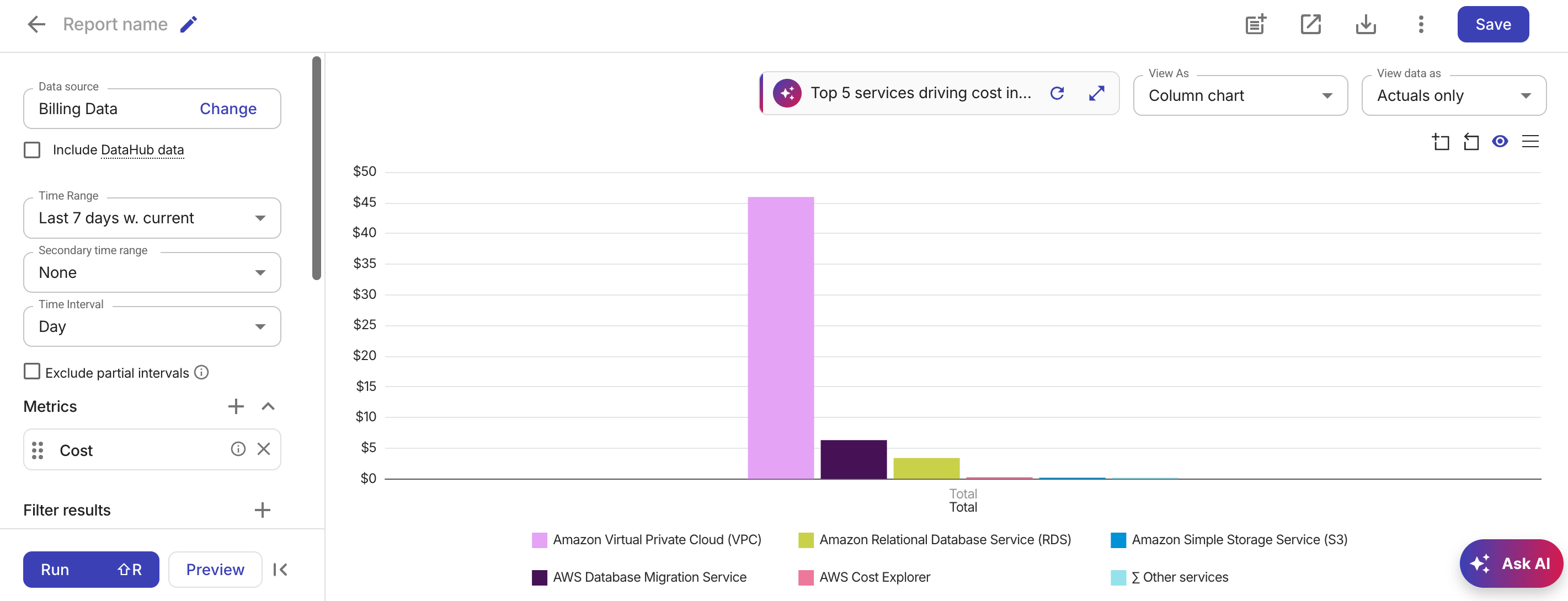
-
生成されたレポートを確認し、必要に応じて調整します。レポート上部の copilot ドックには使用したプロンプトが表示され、コンテキストを失うことなく繰り返し調整できます。
詳細については、レポート設定を編集 を参照してください。
-
新しいレポートに名前を付け、保存 を選択します。
既存のレポートを基に作成する
既存のレポート(プリセットレポート、マネージドレポート、他のユーザーが作成したカスタムレポートなど)を基に、カスタムレポートを作成できます。
メインの レポート ページにいる場合:
-
対象のレポートを探します。
-
レポート行の一番右端にあるケバブメニュー(⋮)を選択します。
-
複製 を選択します。
レポートを表示している場合は、次のいずれかの方法に従ってください。
-
レポートを変更し、名前を付けて保存 を選択して、カスタマイズしたバージョンを新しいレポートとして保存します。
-
レポートタイトルバーのケバブメニュー(⋮)を選択し、レポートを複製 を選択します。
デフォルトビューとして設定する
現在のレポートの設定 を、新しいレポート作成時の個人用デフォルト開始ポイント(デフォルトビュー)として保存するには、次の手順に従ってください。
-
レポートタイトルバーのケバブメニュー(⋮)を選択します。
-
新しいレポートのデフォルトビューとして設定 を選択します。
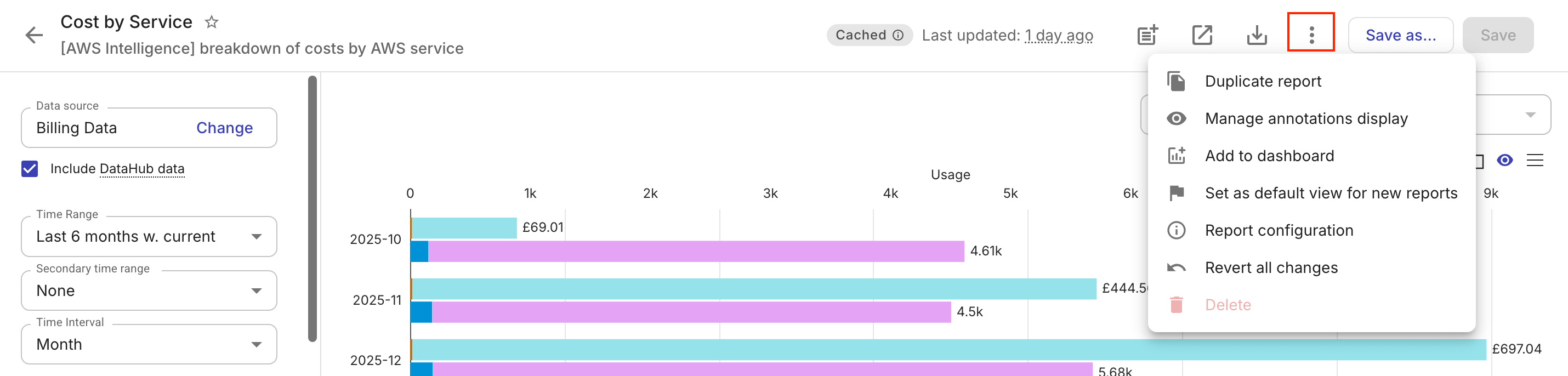
デフォルトビューは、あなたのアカウントに紐づきます。一度設定すると、その後に作成する新しいレポートはすべて、そのデフォルトビューから開始します。
デフォルトビューをクリアすることはできません。現在のデフォルトビューを上書きするには、目的の設定を持つレポートを開き、それを新しいデフォルトビューとして設定してください。
レポートをプレビューする
大規模なデータセットを扱う場合、まずデータのサンプルを使用してレポートを実行すると役立つことがよくあります。待ち時間を短縮することで、フィルター・グループ・その他のレポート設定をすばやく検証および反復し、全データセットを処理する前に設定が正しいことを確認できます。
サンプルデータでレポートを実行するには、実行 の横にある プレビュー を選択します。
プレビューでは、データセット全体の 10% が使用されます。
ベストプラクティス
レポート作成時の精度と有効性を高めるために、以下のベストプラクティスを検討してください。
カーディナリティの高いディメンションをフィルターし、結果を制限する
カーディナリティの高いディメンションとは、一意の値が非常に多いデータ属性です。これらは、ブラウザへデータをダウンロードし、その後グラフまたはテーブルに読み込む前に、レポートが読み取り・ページ分割しなければならない行数を増やし、レポート生成を遅くします。
Project/Account ID、Service、SKU、Resource などのカーディナリティの高いディメンションを扱うときは、必ずフィルターと結果をリミット を行ってください。この方法は、データポイントのリミット や データ取り込みのリミット を回避するうえでも有効です。
Provider を選択する
正確なデータ表現を確保するために、Provider フィルターを手動で設定し、Include DataHub data オプションを確認してください。
たとえば Service is BigQuery のように特定の値でフィルタリングする場合、Provider フィルターは自動的に適用されます。ただし、このフィルターは過去に作成されたレポートに遡っては適用されず、手動で削除した場合も適用されません。さらに、部分一致・正規表現一致・is not 一致を使用している場合、Provider フィルターは自動的には追加されません。
マルチクラウドレポートのコンテキストでは、特定のプロバイダーへのフィルタリングが課題となる場合があります。それでもなお、可能な限り Provider ディメンションフィルターを使用してスキャン対象データ量を最小化することが、ベストプラクティスとされています。
大量の DataHub データを取り込んでいる場合は、レポートの目的に基づき、そのデータを含めるべきかどうかを検討することが重要です。
完全一致でフィルターする
is モードでフィルタリングすることは、最も効率的なレポート構築方法です。等価フィルターを使用することで、スキャンが必要なデータ量が減少し、パフォーマンスが向上します。
正規表現や部分一致など、その他のフィルターモードは検索インデックスを利用しないため、is モードと比較してパフォーマンス向上の効果が低くなります。
予測の使用には注意する
予測 を使用すると、レポートの処理時間が長くなる可能性があることに注意してください。
キャッシュされたレポート
Cache report を選択する場合、キャッシュされたレポートはバックグラウンドジョブとして動作し、バックグラウンドで実行される他のプロセスとリソースを共有することに注意してください。結果として、キャッシュされたレポート のパフォーマンスは、現在のワークロードの影響を大きく受け、かなり変動する可能性があります。