DataHub API 経由でデータを取り込む
前提条件
すでにDoiT API key を作成済みである必要があります。API キーはセキュリティのために GCP Secret Manager に保存できます。
このチュートリアルではデモ目的の架空データを使用しています。実際のシナリオでは、送信前に必ずデータを適切にサニタイズし、たとえば個人を特定できる情報(PII)をマスクしてください。
目的
このチュートリアルでは次の内容を学びます。
-
DataHub API の JSON ペイロードを使用して、複数のデータセットを DoiT の Cloud Analytics(クラウド分析)に取り込む。
-
クラウドの請求データと取り込んだデータを組み合わせて、組織の支出を分析する Cloud Analytics(クラウド分析)レポートを作成する。
ステップ 1:データソースを特定する
組織の支出は以下で構成されます。
-
公開クラウドの請求データ:組織は DoiT から Amazon Web Services と Google Cloud のサービスを購入しています。クラウドの請求データはすでに DoiT の Cloud Analytics(クラウド分析)で利用可能です。
-
サードパーティの費用:組織はビジネス管理に NetSuite を使用しており、毎月請求されます。
-
運用コスト:組織には AMER・APAC・EMEA の 3 つのスーパーリージョンに従業員�がいます。各リージョンには複数の機能チームがあります。従業員コストのデータは CSV ファイルに保存されています。
以下は CSV のサンプルです。
employees.csv
Employee ID,Employee Name,Territory,Team,Month,Cost
E1001,John Doe,AMER,Exec,2024-03-01,$75000
E1001,John Doe,AMER,Exec,2024-04-01,$75000
E1001,John Doe,AMER,Exec,2024-05-01,$75000
E1002,Jane Smith,AMER,Legal and Finance,2024-03-01,$60000
E1002,Jane Smith,AMER,Legal and Finance,2024-04-01,$60000
E1002,Jane Smith,AMER,Legal and Finance,2024-05-01,$60000
E1003,Emily Davis,AMER,R&D,2024-03-01,$116000
E1003,Emily Davis,AMER,R&D,2024-04-01,$116000
E1003,Emily Davis,AMER,R&D,2024-05-01,$116000
E1004,William Brown,AMER,HR and Support,2024-03-01,$56000
E1004,William Brown,AMER,HR and Support,2024-04-01,$56000
E1004,William Brown,AMER,HR and Support,2024-05-01,$56000
E1005,Xiao Ming,EMEA,R&D,2024-03-01,$61000
E1005,Xiao Ming,EMEA,R&D,2024-04-01,$61000
E1005,Xiao Ming,EMEA,R&D,2024-05-01,$61000
E1006,Ahmed Khan,APAC,R&D,2024-03-01,$58000
E1006,Ahmed Khan,APAC,R&D,2024-04-01,$58000
E1006,Ahmed Khan,APAC,R&D,2024-05-01,$58000
netsuite.csv
Territory,Month,Cost
AMER,2024-03-01,$70000
AMER,2024-04-01,$70000
AMER,2024-05-01,$70000
EMEA,2024-03-01,$7500
EMEA,2024-04-01,$7500
EMEA,2024-05-01,$7500
APAC,2024-03-01,$3700
APAC,2024-04-01,$3700
APAC,2024-05-01,$3700
ステップ 2:データの粒度を定義する
全体の支出を分析するには、サードパーティの費用と運用コストを DoiT の Cloud Analytics(クラウド分析)に取り込み、クラウドの請求データと組み合わせる必要があります。
-
NetSuite の費用と従業員コストは別々に取り込み、データソース識別子として
NetSuiteとEmployeesを使用します(Events スキーマのproviderフィールド)。 -
従業員コストのデータについては、DataHub API リクエストのペイロードを作成する際に、
Employee ID、Employee Name、Territory、Teamをカスタムディメンションとして追加します(labelタイプのディメンションを使用)。
ステップ 3:ペイロードを準備してデータを送信する
このステップでは、Flask と Werkzeug を使用して、従業員コストのデータを変換し、API リクエストを送信する Python スクリプトをセットアップします。実際には、同じ目的を達成できる他のツールを選択しても構いません。
【Requirements ファイル】:
requirements.txt
google-cloud-secret-manager
Flask==2.2.5
Werkzeug==2.0.1
pytz
requests
python-dotenv
【Python スクリプト】:
main.py
from flask import request
import time
from pytz import timezone, utc
from google.cloud import secretmanager
import requests
import csv
from datetime import datetime
def access_secret(secret_id):
"""Accesses the specified secret from Secret Manager."""
project_id = GCP_PROJECT # Automatically provided by Cloud Functions
name = f"projects/{project_id}/secrets/{secret_id}/versions/latest"
response = client.access_secret_version(name=name)
return response.payload.data.decode('UTF-8')
def send_api_request(data,doit_api_key):
url = f"https://api.doit.com/datahub/v1/events" #prod
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {doit_api_key}" # Add the Authorization header
}
response = requests.post(url, json=data, headers=headers)
return response
def format_to_iso(date_str):
# Parse the date string to a datetime object assuming the format is YYYY-MM-DD
date = datetime.strptime(date_str, "%Y-%m-%d")
# Format the datetime object to ISO 8601 format with time set to midnight
formatted_date = date.strftime("%Y-%m-%dT%H:%M:%S.00Z")
return formatted_date
def ingest(json_data, doit_api_key):
"""Process and send the JSON data to the API endpoint."""
for item in json_data:
employee_id = item.get("employee_id")
employee_name = item.get("employee_name")
territory = item.get("territory")
team = item.get("team")
month = format_to_iso(item.get("month"))
cost = item.get("cost").replace("$", "").replace(",", "") # Remove $ and commas
api_request_data = {
"events": [{
"provider": "Employees",
"id": f"{employee_id}_{month}",
"dimensions": [
{"key": "Employee_ID", "type": "label", "value": employee_id},
{"key": "Employee_name", "type": "label", "value": employee_name},
{"key": "Territory", "type": "label", "value": territory},
{"key": "Team", "type": "label", "value": team}
],
"time": month,
"metrics": [
{"value": float(cost), "type": "cost"},
{"value": 180, "type": "usage"}, # Example monthly working hours
{"value": 0, "type": "savings"} # Example savings (e.g., from benefits or discounts)
]
}]
}
max_retries = 6
retry_delay = 10 # seconds
for attempt in range(max_retries + 1):
response = send_api_request(api_request_data, doit_api_key)
if response.status_code in [200, 201]:
break
elif response.status_code == 429:
print(f"API request rate limited. Attempt {attempt + 1} of {max_retries}. Retrying in {retry_delay} seconds.")
if attempt < max_retries:
time.sleep(retry_delay)
else:
print("Maximum retries reached. Exiting.")
else:
print(f"API request failed with status code: {response.status_code} {response.text}")
break
def access_secret(secret_id):
"""Accesses the specified secret from Secret Manager."""
project_id = GCP_PROJECT
name = f"projects/{project_id}/secrets/{secret_id}/versions/latest"
response = client.access_secret_version(name=name)
return response.payload.data.decode('UTF-8')
def ingest_employees(file_path, doit_api_key):
"""Read data from a CSV file and use the ingest function to ingest it."""
with open(file_path, mode='r') as csv_file:
csv_reader = csv.DictReader(csv_file)
for row in csv_reader:
json_data = [{
"employee_id": row["Employee ID"],
"employee_name": row["Employee Name"],
"territory": row["Territory"],
"team": row["Team"],
"month": row["Month"],
"cost": row["Cost"]
}]
ingest(json_data, doit_api_key)
def ingest_employee_cost(request):
doit_api_key = access_secret('DOIT_API_KEY')
print(f"ingesting employees cost from CSV")
file_path = 'employees.csv' # Path to your CSV file
ingest_employees(file_path, doit_api_key)
# Return the response
return f'Done'
client = secretmanager.SecretManagerServiceClient()
GCP_PROJECT = "your-gc-project"
if __name__ == "__main__":
ingest_employee_cost("")
誤ったデータを取り込んだ場合は、取り込み後 90 分経過するとイベントを DELETE できます。
NetSuite のデータを取り込むために、もう一度 API リクエストを実行してください。
ステップ 4:コスト分析を実施する
API リクエストが成功していれば、約 15 分後に結合済みデータセットを使ったコスト分析に進めます。
-
DoiT コンソールの上部ナビゲーションのメガメニューから[Reporting and analytics]を選択し、[Reports]を選択してください。
-
新しいレポートを作成します。左ペインの[Data source]で[Include DataHub data]チェックボックスを選択してください。
取り込んだデータが利用可能になるまで、このチェックボックスはグレー表示です。

[Filter providers]オプションを使用すると、利用可能なすべてのデータセットを確認できます。
-
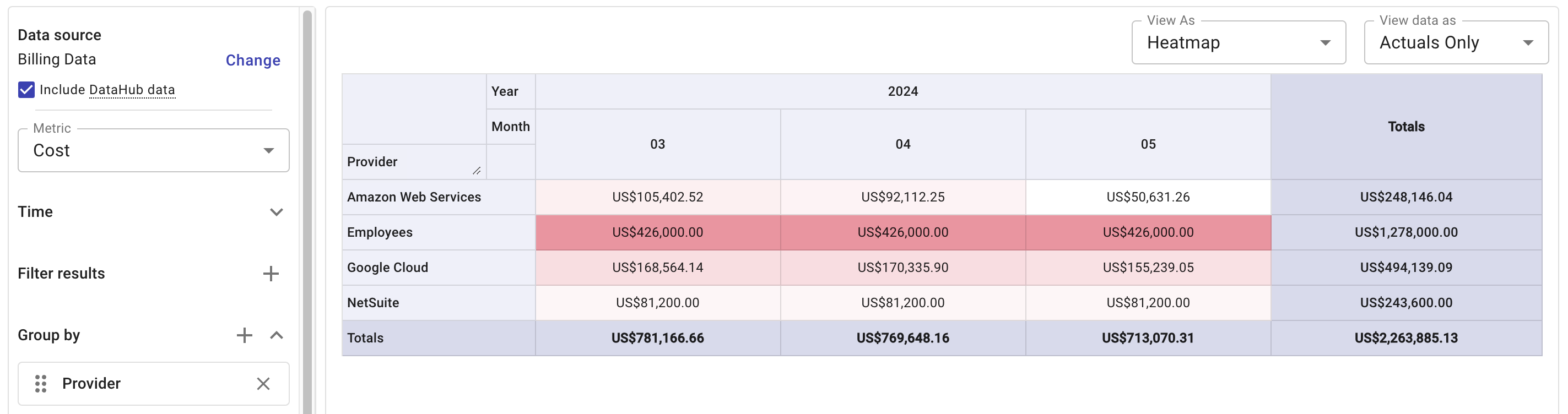
dimensions and labels を指定してレポートを実行してください。
- このサンプルレポートは、データセットごとの月次コストを表示します。
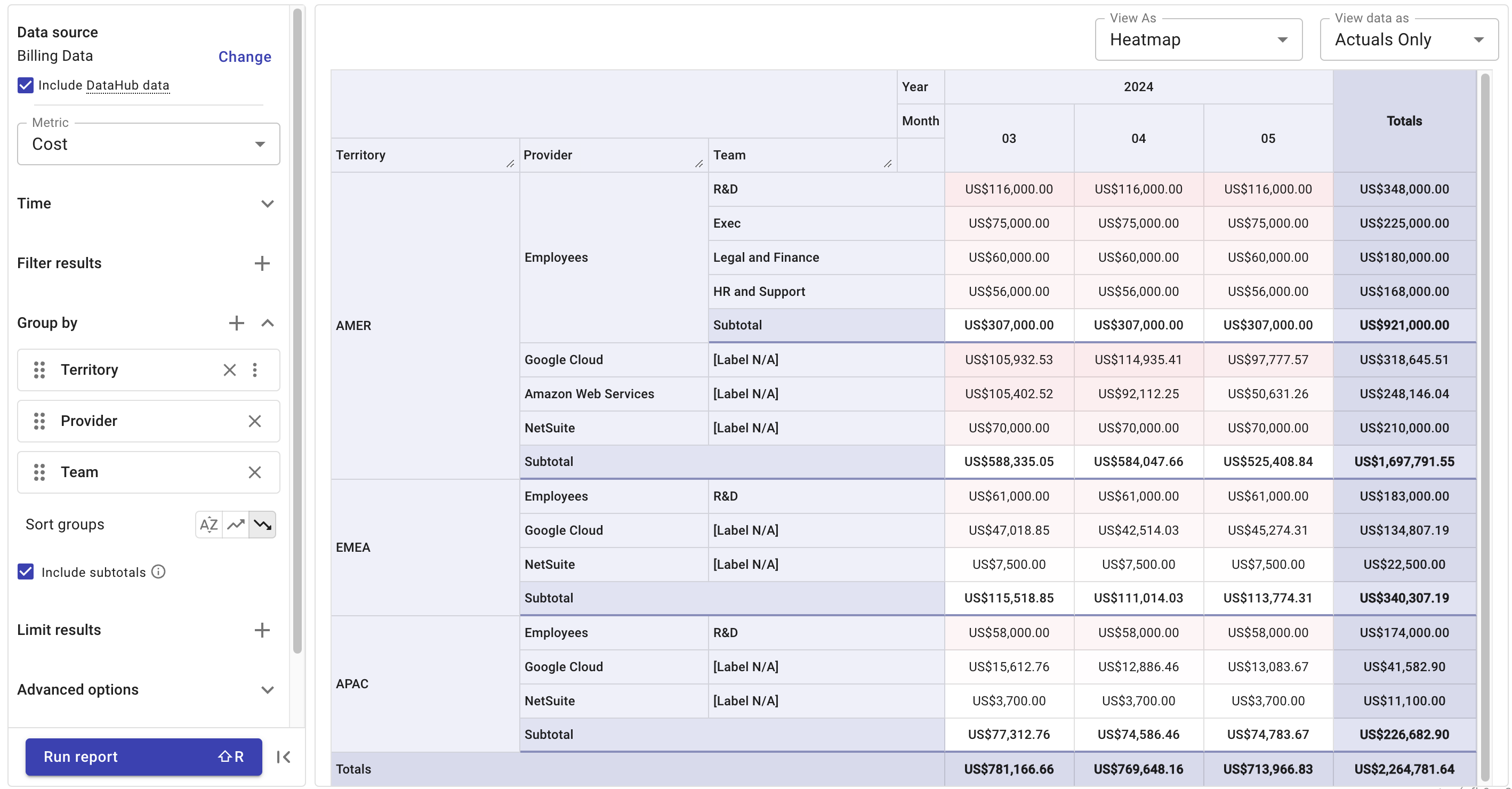
- すべてのデータセットに
Territoryラベルを適用している場合、スーパーリージョン別にコストの内訳を表示できます。
ステップ 5(任意):ダッシュボードを設定する
取り込んだデータで 1 件以上のレポートを作成したら、カスタマイズ可能なダッシュボードにレポートを追加 できます。