AI データの操作
DoiT は、次のプロバイダが提供する AI サービスをサポートしています:AWS(Amazon Bedrock)、Google Cloud(Vertex AI)、Microsoft Azure(Azure Machine Learning)、Databricks、Anthropic、OpenAI。
GenAI providers を接続すると、AI のコストと使用状況の分析およびモニタリングを開始できます。
Cloud Analytics における AI データ
DoiT Cloud Analytics は AI データを 1 時間ごとに更新します。
制限事項
-
Databricks:現在、利用できるのはコストデータのみです。トークン使用量データは今後サポート予定です。
-
OpenAI:OpenAI のコストデータは最終的な請求額を反映しますが、使用量データはアクティビティのモニタリング用です。そのため、レポートに表示されるコストが、実際の使用量と必ずしも一致しない場合があります。詳細が必要な場合は、OpenAI API Usage Dashboard を確認してください。
- OpenAI の音声入力トークン:OpenAI Costs API は、キャッシュありとキャッシュなしの音声入力トークンのコストをまとめて集計します。このため、GenAI Intelligence では OpenAI の音声 SKU をキャッシュありとキャッシュなしに分けて表示しておらず、音声入力トークンのコストは常に合算されます。
dimensions および metrics を通じて AI データを取得できます。以下に、DoiT の用語と AI の用語の対応表を示します。
基本メトリクス
| DoiT term | AI term | AI definition |
|---|---|---|
cost | cost | 特定のリソースまたは使用量に対する合計コスト。 |
usage | usage | トークンの使用量。加えて、使用メトリックには、トラッキング対象の特定のサービス・モデル・オペレーションに応じて、秒・バイト・文字数などに基づく消費量も含まれます。 |
標準ディメンション
次の表は、DoiT プラットフォームと連携されているすべての AI モデルで利用可能な標準ディメンションを示しています。
| DoiT term | Description |
|---|---|
| Billing Account | AI アカウント内の特定の組織を表す一意の識別子。 |
| Project ID/Account ID | AI プロバイダのワークスペースを表す一意の識別子。 |
| Service ID/Service Description/SKU Description | 使用されている AI プロダクトや機能の種類を表す高レベルの説明。例:Completions API、Embeddings API、Claude haiku3.5 Usage - Input tokens、Web Search Usage。 |
| SKU ID/SKU description | 利用している AI サービス内の、より細分化さ��れた課金単位。例:chatgpt-4o-latest, input、text-embedding-3-large、claude-3-5-haiku-20241022, input_tokens、claude-sonnet-4-20250514, output_tokens。 |
| Usage | 利用の主な単位。ほとんどのプロバイダでは主な単位は token ですが、利用している AI サービスに応じて他の単位も使用されます。 |
| Operation | AI サービスによって実行される、個別の課金対象アクション。例:input、cached input、web_search、image。 |
| Provider | AI プロバイダの名前。例:OpenAI、Anthropic、Google Cloud、Amazon Web Services、Azure、Databricks。 |
GenAI ラベル
以下は、DoiT プラットフォームで使用できる GenAI システムラベルです。GenAI システムラベルは GenAI セクションにグループ化されています。
| Label | Description | Provider |
|---|---|---|
| API Key ID | AI キーの一意の識別子。 | Anthropic, OpenAI |
| API Key Name | AI API キーの名前。 | Anthropic, OpenAI |
| Base Model | AI モデル提供を表す識別子。例:gpt-4.1、claude-haiku-4.5。 | Anthropic, OpenAI |
| Cached | コスト最適化のためにキャッシュされたトークンが使用されたかどうかを示します:true または false。 | Anthropic, Azure, OpenAI |
| Consumption Model | AI サービスに使用される料金モデル:PAYG(従量課金制)または Provisioned Throughput。 | Azure, GCP |
| Context Window | 使用された AI モデルに適用されるコンテキストウィンドウの制限。次のいずれか:0-200k、200k-1M。 | Anthropic |
| Feature | 使用されている AI 機能またはサービス機能の種類。Vertex AI の例:Model Serving、Model Serving via Model Garden、Vertex Colab、Metadata storage。Microsoft Azure の例:Model Serving、Audio Generation、Embeddings。 | Azure, GCP |
| GenAI Spend | AI プロバイダを問わず、あらゆる生成 AI ワークロードのコスト。 | Anthropic, AWS, Azure, Databricks, GCP, OpenAI |
| Is Model Serving | サービスがモデルを実際に�提供しているかどうかを示します:true または false。Vertex AI と Amazon Bedrock で利用可能。 | Azure, GCP |
| Media Format | 複数のメディアタイプをサポートするモデルにおいて、サービスが音声・画像・テキストのいずれを処理していたかを区別するメディア形式。例:audio。 | Anthropic, AWS, OpenAI |
| Model | AI モデル提供を表す識別子。例:gpt-4o-audio-preview。 | Anthropic, AWS, Azure, Databricks, GCP, OpenAI |
| Model Family | 共通のアーキテクチャと学習手法を共有する関連 AI モデル群。例:Claude、Gemini、GPT-5、Mistral。 | Anthropic, AWS, Azure, Databricks, GCP, OpenAI |
| Model Version | AI モデル提供のバージョン。例:2024-12-17。 | Anthropic, OpenAI |
| Organization Name | AI 組織を表す一意の識別子。 | Anthropic, AWS, Azure, OpenAI |
| Project | Anthropic における Workspace ID と同じ意味。 | Anthropic |
| Resolution | 単一の使用における画像の解像度。画像処理をサポートする OpenAI モデルで使用されます。 | OpenAI |
| Service Tier | 特定のワークフロー向けに API の優先度を制御するために、Anthropic API で使用されるサービスレベル。Priority、Standard、Batch のいずれか。 | Anthropic |
| Unit Category | Azure AI サービスの課金単位タイプ。Commitment、Tokens、Batch、Time または Time Short、Period、Request などの値があります。 | Azure |
| Usage Type | AI モデルとの対話におけるトークンの流れの方向:input(モデルに送信されるトークン)または output(モデルによって生成されるトークン)。 | Anthropic, AWS, Azure, Databricks, GCP, OpenAI |
| User ID | AI 組織内の特定ユーザーを表す一意の識別子。 | Anthropic, OpenAI |
| User Name | AI 組織内の特定ユーザーの名前。 | Anthropic, OpenAI |
| Workspace | Anthropic コンソールにおける Workspace 名。 | Anthropic |
| Workspace ID | Anthropic コンソールにおける Workspace の ID。 | Anthropic |
レポート例
GenAI Intelligence dashboard には、GenAI のコストと使用状況の分析をすぐに開始できるよう、複数のプリセットレポートウィジェットが用意されています。プリセットレポートの設定を調整することも、独自のレポートをゼロから作成して GenAI データをより深く分析することもできます。
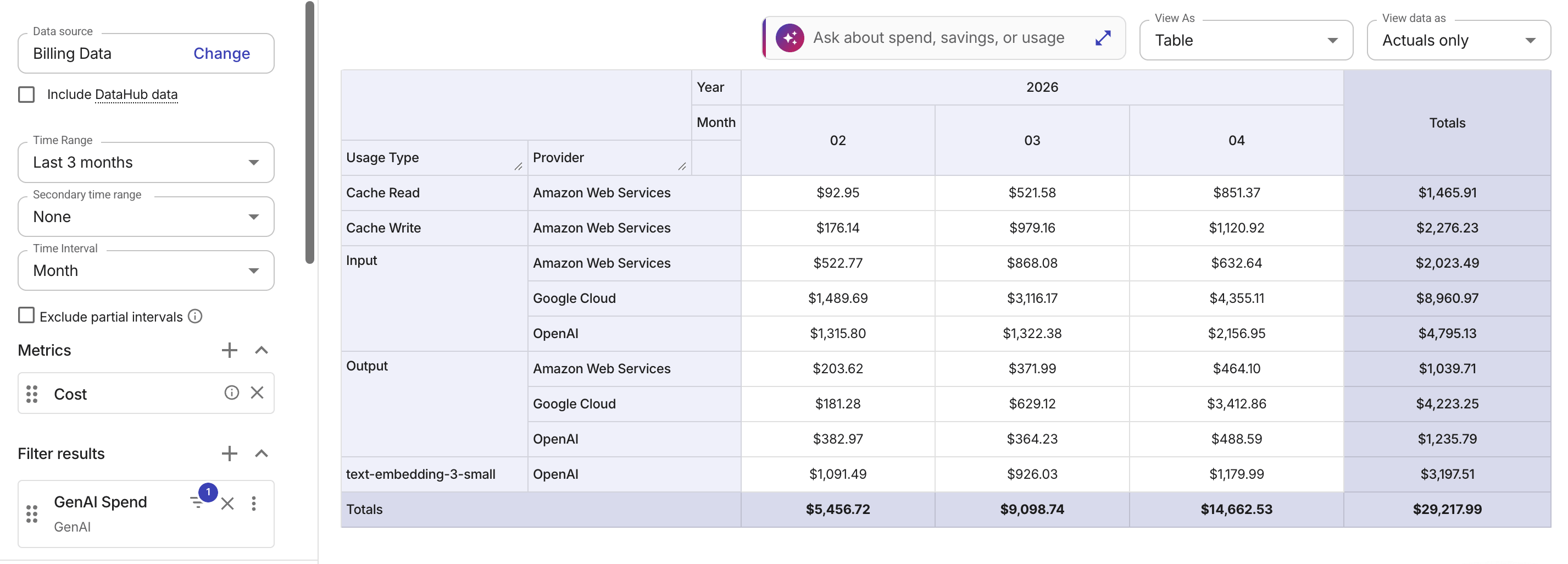
Usage type 別コスト
以下の例では、標準化された Usage Type ディメンションごとに、プロバイダをまたいだ AI コストをグループ化しています。
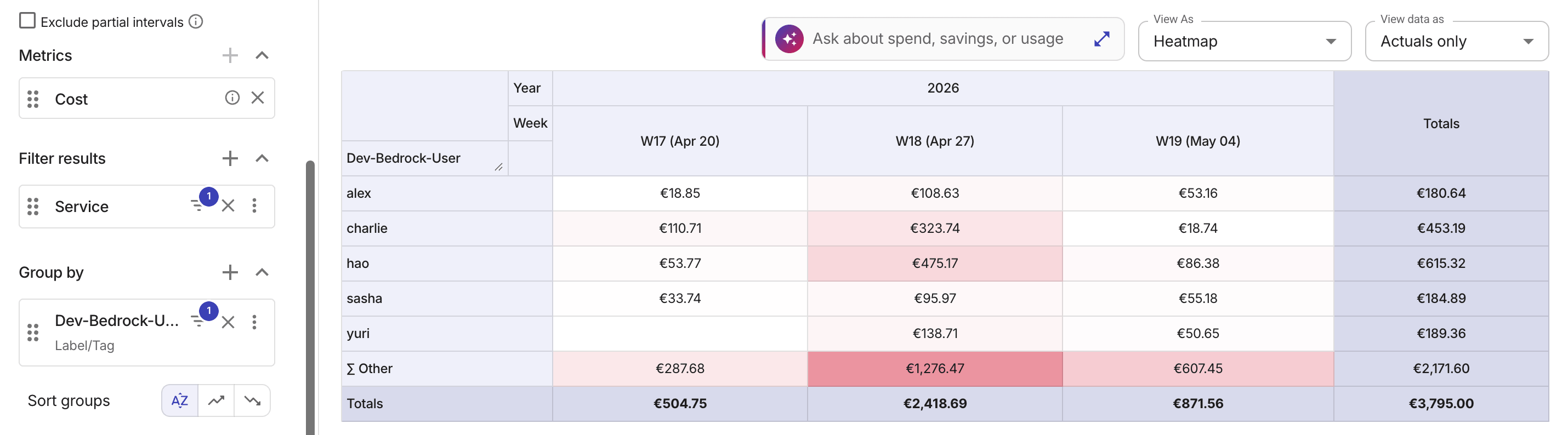
ユーザー別の Amazon Bedrock コスト
標準的な AWS 請求では、Bedrock のコストはモデルとリージョンごとに集計されます。よりきめ細かいコストトラッ��キングとアロケーションのために、AWS は Application Inference Profiles の利用を推奨しています(AWS re:Post 記事:How to Track and Limit Amazon Bedrock Usage by User を参照してください)。
DoiT プラットフォームでユーザー別に Bedrock 使用量をトラッキングするには、次の手順を実行してください。
-
Bedrock コンソールまたは API を使用して、ユーザーごとに AIP を作成してください。
-
カスタムコストアロケーションタグを適用し、推論 API 呼び出しではベースモデルの ARN ではなく AIP の ARN を使用してください。
-
DoiT プラットフォームで AWS コストアロケーションタグを有効化します。アカウントタイプによっては、タグを再有効化する 必要がある場合があります。
タグが AWS の請求データに現れてから Cloud Analytics のレポートに表示されるまでに、6–8 時間かかる場合があります。新しいタグの場合、最大で 24 時間かかることがあります。レイテンシーやその他の制約については、Limitations を参照してください。
以下の例は、過去 3 週間における Amazon Bedrock コストの上位 5 ユーザーを、カスタムコストアロケーションタグ別にグループ化して表示したものです。