クラスタ利用率ダッシュボード
クラスタ利用率ダッシュボードでは、ワークロード単位のリソース使用メトリクスを提供します。
必要な権限
- Cloud Analytics(クラウド分析)User
クラスタ利用率ダッシュボードへのアクセス
クラスタ利用率ダッシュボードにアクセスするには、Kubernetes Intelligence ダッシュボードのクラスタ一覧から対象のクラスタを選択します。
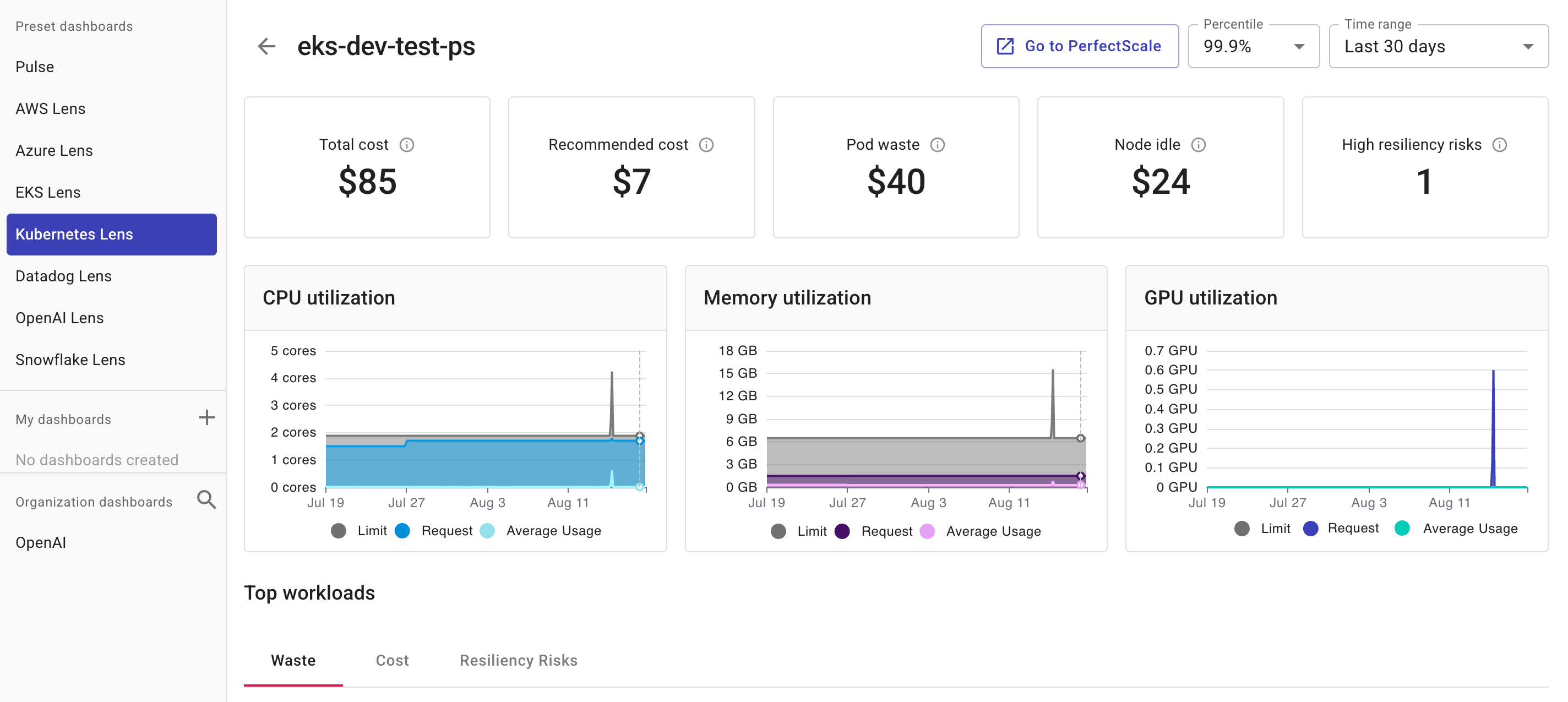
クラスタ利用率ダッシュボードは次の要素で構成されています。
一般設定
一般設定はダッシュボードの右上にあります。
-
Go to PerfectScale:PerfectScale のサインインページを起動します。まだ PerfectScale に新規登録していない場合は、開始用の招待が送信されます。
-
Percentile:利用率の時系列データ集合において、所定のパーセントのデータがその値以下となる基準値を指定します。たとえば 95% パーセンタイルは、値の 95% がその点以下であることを意味します。使用パターンの把握に役立ちます。
-
Time range:データ収集期間を指定します。期間はデータの粒度に影響します。
-
直近 1・4・12 時間、直近 1 日:10 分粒度
-
直近 3・7 日:1 時間粒度
-
直近 14・30 日:1 日粒度
-
サマリー情報
-
Total cost:クラウドの請求データに基づく、選択した期間のクラスタのコスト。
-
Recommended cost:PerfectScale の推奨に基づいて達成可能な推奨コスト。
-
Pod waste:Kubernetes Intelligence エージェントが収集した利用率データに基づく、過剰プロビジョニングされた Pod のコスト。
-
Node idle:Kubernetes Intelligence エージェントが収集した利用率データに基づく、アイドル状態のノードのコスト。
-
High resiliency risks:
At RiskインジケーターがHighの場合に PerfectScale によって特定された、クラスタ内の高いレジリエンシーリスクを持つワークロードの総数。詳細はResiliency alerts を参照してください。
利用率チャート
クラスタ利用率ダッシュボードのメインセクションには、選択した期間とパーセンタイルにおけるクラスタのメモリ・CPU・GPU の利用率を示す 3 つのチャートが含まれます。
-
CPU utilization:CPU リソース(コア)の上限、要求、平均使用量を表示します。CPU 利用率が高い場合、計算量の多いワークロードが実行されているか、CPU リソースの追加が必要である可能性があります。
-
Memory utilization:メモリリソース(GB)の上限、要求、平均使用量を表示します。メモリ利用率が高い場合、メモリ集約型ワークロードが実行されているか、メモリリソースの追加が必要である可能性があります。
-
GPU utilization:GPU リソースの上限、要求、平均使用量を表示します。GPU 利用率が高い場合、機械学習やデータ処理などのグラフィックスまたは計算集約型ワークロードが実行されているか、GPU リソースの追加が必要である可能性があります。
注意PerfectScale は現在、NVIDIA Data Center GPU Manager(DCGM)のみをサポートしています。詳細はPerfectScale: GPU optimization を参照してください。
チャートにカーソルを合わせると、異なる時点の数値を表示できます。
-
Limit:クラスタに割り当てられた CPU・メモリ・GPU リソースの合計量。
-
Request:クラスタ上のワークロードによって要求された CPU・メモリ・GPU リソースの合計量。
-
Average usage:クラスタ上で実行中のワークロードが消費した CPU・メモリ・GPU リソースの平均合計量。
Waste・コスト・レジリエンシーリスク
クラスタ利用率ダッシュボードの下部には、選択した期間にクラスタ上で実行された上位ワークロードの詳細なリソース使用情報が表示されます。
各タブには、それぞれ上位 20 件のワークロードが表示されます。Waste タブでは Waste 順、Cost タブではコスト順、Resiliency risks タブでは高いレジリエンシーリスクの件数順で並び替えられたワークロードを表示します。
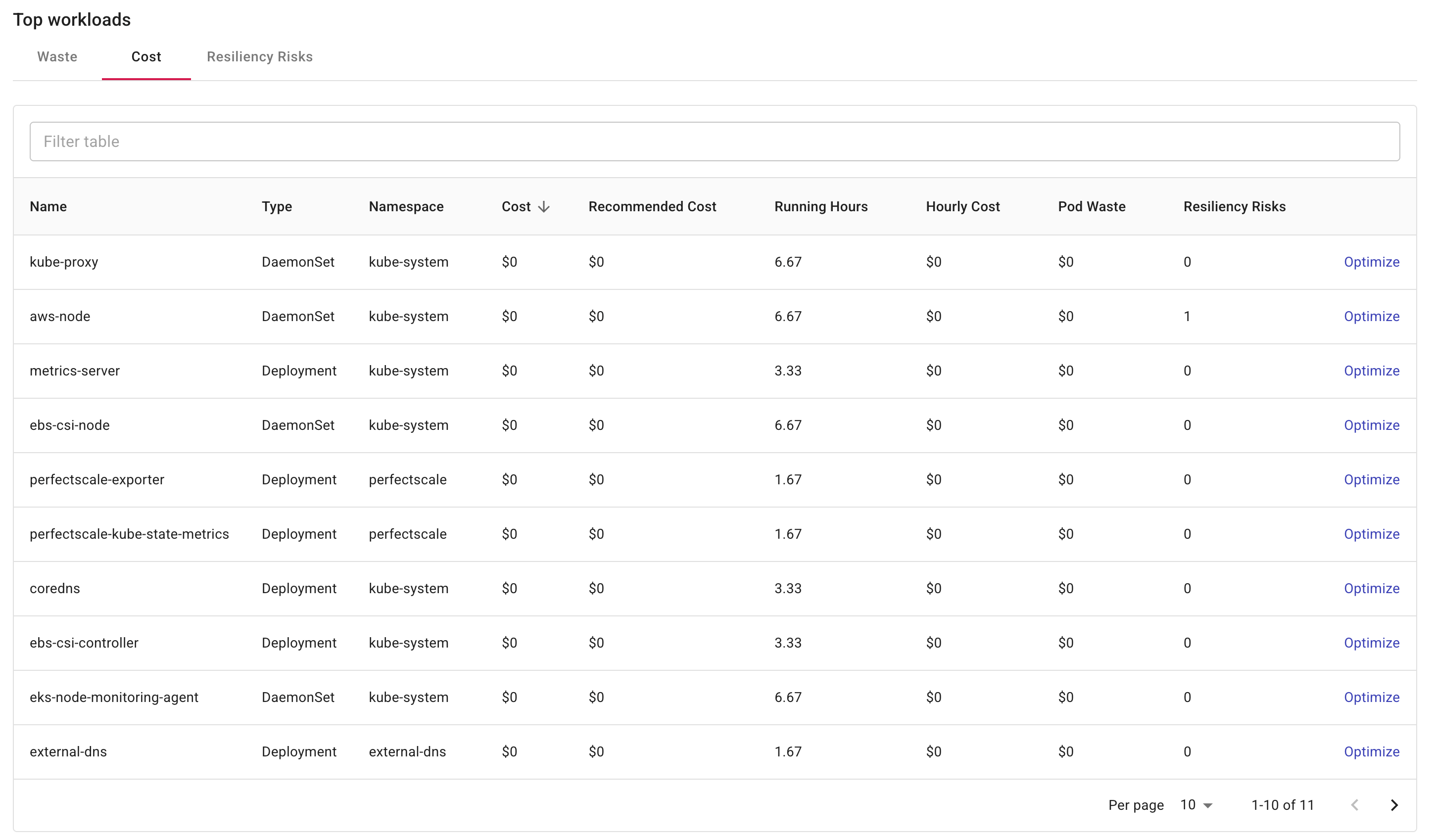
-
Name:ワークロード名。
-
Type:ワークロードのリソース種別(例:Pod・Deployment・DaemonSet・Jobs)。
-
Namespace:ワークロードの Namespace。
-
Cost:ワークロードの総コスト。
-
Recommended cost:PerfectScale の推奨に基づいて達成可能な推奨コスト。
-
Running hours:ワークロードの稼働時間(時間)。
-
Hourly cost:ワークロードの時間単価。
-
Pod waste:そのワークロードにおける過剰プロビジョニングされた Pod のコスト。
-
Resiliency risks:そのワークロードで特定された高いレジリエンシーリスクの件数。詳細はResiliency alerts を参照してください。
ページ下部の Optimize または Go to PerfectScale を選択して、PerfectScale のページを起動できます。